데이터시각화(R)_Tibbles2
6. Combining multiple operations with the pipe
- 각 도착지별로 distance 와 average delay 의 관계 살펴보기
library(tidyverse)
library(nycflights13)
flights
by_dest = group_by(flights,dest)
by_destdelay <- summarise(by_dest,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
)- count: 행의 개수를 나타내는 변수, n() 함수를 사용하여 계산
- dist: distance 변수의 평균값을 나타내는 변수로, mean(distance, na.rm=TRUE)를 사용하여 계산
- delay : arr_delay 변수의 평균값을 나타내는 변수로, 결측값이 있는 경우 해당 값을 제외하고 평균을 계산
→ by_dest 데이터셋에서 출발지별(dest)로 그룹화된 항공편 정보에 대한 요약 통계량 저장된 delay 데이터프레임 생성
ggplot(delay,aes(dist,delay))+geom_point()
ggplot(delay,aes(count))+geom_histogram()
- delay 데이터 프레임 필터링
delay <- filter(delay, count > 20, dest != "HNL")
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE)- delay 데이터 프레임 생성: count열의 값이 20보다 크고, dest 열의 값이 HNL이 아닌 행들로 구성
- ggplot() 함수를 사용하여 시각화 작업
- size(점의 크기)는 count 열과 매핑되어 표시
- alpha(점의 투명도)가 1/3으로 설정되어 부분적으로 투명한 점으로 나타냄
- geom_smooth(): 평활선 추가/ se=FALSE: 평활선 주변에 신뢰구간 제외하고 평활선만 그림을 의미

→ 각 점의 크기는 해당 출발지별 항공편 수(count)와 관련이 있다.
위의 그림을 그리기 위한 자료 준비 단계
1. flights 자료를 destination 에 따라 그룹으로 나누기
2. 각 그룹별로 distance, average delay, 그리고 flight 수 구하기
3. 가장 먼 Honolulu 와 비행건수가 20 이하인 자료 제거 • 자료준비를 위해 pipe %>%를 이용하면 간편
delays <- flights %>%
group_by(dest) %>%
summarise(
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
) %>%
filter(count > 20, dest != "HNL")- summarise : 각 그룹의 요약 통계량 계산
- count : 해당 출발지의 항공편 수를 나타내는 변수
- dist : 해당 출발지의 거리 평균값을 나타내는 변수
- delay : 해당 출발지의 지연시간 평균값을 나타내는 변수
- count > 20 과 dest != 'HNL'을 적용하여 행들을 필터링 진행
→ 결과적으로 반환된 데이터프레임인 delays에는 필터링된 조건에 맞는 출발지별 항공편 정보의 요약 통계량이 저장됩니다. 이 데이터프레임은 필요한 정보만 포함하며, 항공편 수가 20보다 크고 출발지가 "HNL"이 아닌 경우에 대해서만 처리되었습니다.
- na.rm=TRUE 옵션은 통계량 계산 전에 NA 를 모두 제거한 후 계산하기 위한 것(결측값 제거)
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))- year, month, day 그룹화 후 dep_delay 평균값 계산
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay, na.rm = TRUE))- na.rm=TRUE : 결측값이 있는 경우 해당 값을 제외하고 평균 계산토록 지정
- 결측값 갯수 구하기: sum(!is.na(x)): missing 이 아닌 자료의 갯수
flights %>%
group_by(year, month, day) %>%
summarise(n = n(),
na_n = sum(is.na(dep_delay)))- n() 함수는 각 그룹 내에서의 행 수를 계산합니다
- is.na(dep_delay)는 dep_delay 변수가 결측값인지 여부에 대한 논리형 벡터를 반환하며, 이 값을 합산하여 결측값인 개수를 구합니다.
→ 결과적으로 반환된 데이터프레임에는 연도, 월, 일별로 그룹화된 정보가 포함됩니다. 각 그룹마다 해당하는 행의 개수 (n)와 dep_delay 변수 중 결측값인 개수 (na_n)가 저장되어 있습니다.
- Delay 분포 살펴보기
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay)
)- tailnum(항공기 번호)별 그룹화
- arr_delay(도착 지연시간)의 평균값 계산
ggplot(data = delays, mapping = aes(x = delay)) +
geom_freqpoly(binwidth = 10)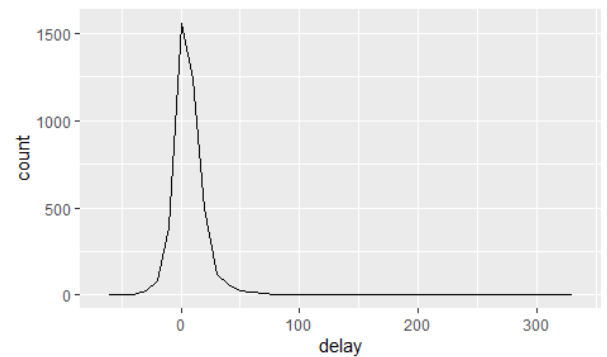
- 다각형 생성위해 geom_greqpoly 함수 호출
- binwidth = 10 : x축 범위 내 막대의 너비 10으로 설정
- y축: 해당 값 범위 내에서의 항공기 개수에 따라 결정됨
→ 300 분 이상의 평균 delay 인 비행기가 있음. 좀 더 자세히 살펴보기 위해 delay 와 비행건수 간의 산점도를 그려보기
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)- mean(arr_delay, na.rm=TRUE)는 결측값이 있는 경우 해당 값을 제외하고 도착 지연 시간의 평균값을 계산
- n() : 각 그룹 내에서의 행 수를 계산
→ 각 항공기에 대한 도착 지연 정보와 관련된 요약 통계량 포함
- alpha 옵션을 넣어서 점이 조금 더 잘 보이게 설정
ggplot(data = delays, mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)
→ 평균 300 이상이긴 하지만 비행건수가 매우 작음을 알 수 있음
- 비행 건수가 25번 이상인 것들만 추출
delays %>%
filter(n > 25) %>%
ggplot(mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)→ 결과적으로 반환된 시각화 객체에는 행 수(n)가 25보다 큰 항공기에 대한 도착 지연시간 평균값의 산점도가 그려집니다. x축은 해당 항공기의 행 수 (n), y축은 해당 항공기의 도착 지연시간 평균값 (delay)을 나타냅니다. 각 점의 위치와 밀집 정도는 해당 항공기의 도착 지연 정보와 관련이 있습니다.

- %>% : 파이프 연산자로 데이터나 결과를 함수로 전달할 때 사용됨 / 가독성 향상
Useful summary functions
not_cancelled %>%
group_by(year, month, day) %>%
summarise(
avg_delay1 = mean(arr_delay),
avg_delay2 = mean(arr_delay[arr_delay > 0])
)can override using the `.groups` argument.
# A tibble: 365 × 5
# Groups: year, month [12]
year month day avg_delay1 avg_delay2
<int> <int> <int> <dbl> <dbl>
1 2013 1 1 12.7 32.5
2 2013 1 2 12.7 32.0
3 2013 1 3 5.73 27.7
4 2013 1 4 -1.93 28.3
5 2013 1 5 -1.53 22.6
6 2013 1 6 4.24 24.4
7 2013 1 7 -4.95 27.8
8 2013 1 8 -3.23 20.8
9 2013 1 9 -0.264 25.6
10 2013 1 10 -5.90 27.3
# ℹ 355 more rows
# ℹ Use `print(n = ...)` to see more rows
- 자료의 퍼짐 정도를 확인: sd(x), IQR(x), mad(x)
not_cancelled %>%
group_by(dest) %>%
summarise(distance_sd = sd(distance)) %>%
arrange(desc(distance_sd))- dest(도착지별) 그룹 후 distance(거리)의 sd(표준편차) 계산
- arrange(desc(distance_sd)): 거리 표준편차 기준으로 내림차순 정렬
→ 결과적으로 반환된 데이터프레임에는 도착지(dest)와 해당 도착지의 거리 표준편차 (distance_sd)가 저장됩니다. 이렇게 생성된 데이터프레임은 도착지별로 거리 변동성 정보와 관련된 요약 통계량을 포함하고 있습니다. 정렬 단계에서는 거리 표준편자가 큰 순서대로 정렬되어 있으므로, 가장 변동성이 큰 도착지부터 나열됩니다 (내림차순)
일별로 가장 먼저, 그리고 가장 마지막에 비행기가 출발하는 시간은?
not_cancelled %>%
group_by(year, month, day) %>%
summarise(
first = min(dep_time),
last = max(dep_time)
)# A tibble: 365 × 5
# Groups: year, month [12]
year month day first last
<int> <int> <int> <int> <int>
1 2013 1 1 517 2356
2 2013 1 2 42 2354
3 2013 1 3 32 2349
4 2013 1 4 25 2358
5 2013 1 5 14 2357
6 2013 1 6 16 2355
7 2013 1 7 49 2359
8 2013 1 8 454 2351
9 2013 1 9 2 2252
10 2013 1 10 3 2320
# ℹ 355 more rows
# ℹ Use `print(n = ...)` to see more rows
- first(x), nth(x, 2), last(x)
not_cancelled %>%
group_by(year, month, day) %>%
summarise(
first_dep = first(dep_time),
last_dep = last(dep_time)
)# A tibble: 365 × 5
# Groups: year, month [12]
year month day first last
<int> <int> <int> <int> <int>
1 2013 1 1 517 2356
2 2013 1 2 42 2354
3 2013 1 3 32 2349
4 2013 1 4 25 2358
5 2013 1 5 14 2357
6 2013 1 6 16 2355
7 2013 1 7 49 2359
8 2013 1 8 454 2351
9 2013 1 9 2 2252
10 2013 1 10 3 2320
# ℹ 355 more rows
# ℹ Use `print(n = ...)` to see more rows1. group_by(year, month, day)를 사용하여 연도(year), 월(month), 일(day)별로 그룹화합니다.
2. summarise() 함수를 사용하여 각 그룹에서 출발 시간 (dep_time)의 첫 번째 값을 first_dep, 마지막 값을 last_dep로 계산합니다.
- first(dep_time)은 해당 그룹 내에서 출발 시간의 첫 번째 값을 반환합니다.
- last(dep_time)은 해당 그룹 내에서 출발 시간의 마지막 값을 반환합니다.
→ 결과적으로 반환된 데이터프레임에는 연도, 월, 일별로 그룹화된 정보가 포함됩니다. 각 그룹마다 출발 시간의 첫 번째 값 (first_dep)과 마지막 값 (last_dep)이 저장되어 있습니다. 이렇게 생성된 데이터프레임은 날짜별로 출발 시간 정보와 관련된 요약 통계량을 포함하고 있습니다.
- 위의 것과 비교
not_cancelled %>%
group_by(year, month, day) %>%
mutate(r = min_rank(desc(dep_time))) %>%
filter(r %in% range(r))
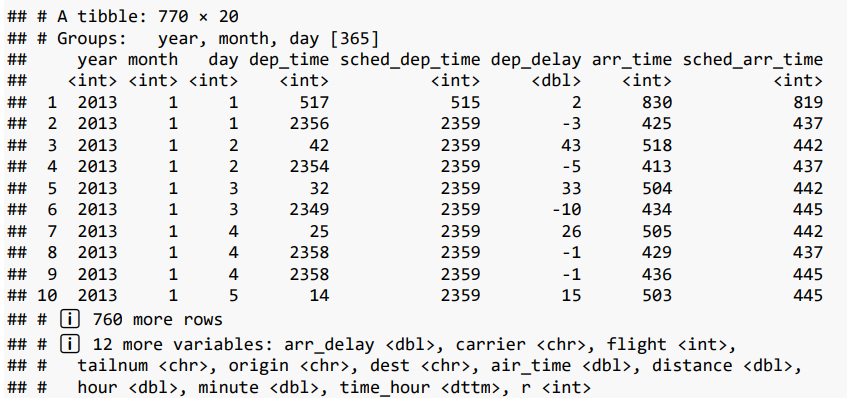
위 코드를 실행하면 not_cancelled 데이터셋을 사용합니다. %>% 연산자를 사용하여 다음과 같은 작업들을 순차적으로 수행합니다:
- group_by(year, month, day)를 사용하여 연도(year), 월(month), 일(day)별로 그룹화합니다.
- mutate() 함수를 사용하여 각 그룹 내에서 출발 시간 (dep_time)의 내림차순으로 순위를 매기고, 새로운 변수 r에 할당합니다.
- desc(dep_time)은 출발 시간을 내림차순으로 정렬합니다.
- min_rank() 함수는 정렬된 값들의 숫자적인 등수를 계산합니다.
- filter(r %in% range(r))를 사용하여 변수 r이 최소 순위와 최대 순위 사이에 있는 행들만 필터링합니다.
→ 결과적으로 반환된 데이터프레임은 연도, 월, 일별로 그룹화되며 각 그룹에서 출발 시간의 등수 정보가 추가된 상태입니다. 이후 필터링 단계에서는 등수가 최소 등수와 최대 등수 사이인 행들만 남게 됩니다. 이렇게 생성된 데이터프레임은 충족하는 조건에 따라 충분히 가까운 혹은 중요한 특정 기준에 따라 선택된 관측치만 포함하고 있습니다.
가장 다양한 항공사에서 노선을 제공하고 있는 목적지는?
not_cancelled %>%
group_by(dest) %>%
summarise(carriers = n_distinct(carrier)) %>%
arrange(desc(carriers))# A tibble: 104 × 2
dest carriers
<chr> <int>
1 ATL 7
2 BOS 7
3 CLT 7
4 ORD 7
5 TPA 7
6 AUS 6
7 DCA 6
8 DTW 6
9 IAD 6
10 MSP 6
# ℹ 94 more rows
# ℹ Use `print(n = ...)` to see more rows위 코드를 실행하면 not_cancelled 데이터셋을 사용합니다. %>% 연산자를 사용하여 다음과 같은 작업들을 순차적으로 수행합니다:
- group_by(dest)를 사용하여 도착지(dest)별로 그룹화합니다.
- summarise() 함수를 사용하여 각 그룹에서 항공사 (carrier)의 고유한 개수인 carriers를 계산합니다.
- n_distinct(carrier)는 해당 그룹 내에서 항공사의 고유한 개수를 반환합니다.
- arrange(desc(carriers))를 사용하여 항공사 개수 기준으로 내림차순으로 정렬합니다.
→ 결과적으로 반환된 데이터프레임에는 도착지(dest)와 해당 도착지에서 운영되는 항공사의 고유한 개수 (carriers)가 저장됩니다. 이렇게 생성된 데이터프레임은 도착지별로 다양한 항공사가 운영하는 횟수와 관련된 요약 통계량을 포함하고 있습니다. 정렬 단계에서는 항공사 개수가 많은 순서대로 정렬되어 있으므로, 가장 많은 항공사가 운영하는 도착지부터 나열됩니다 (내림차순)
가장 많은 비행기가 제공되는 목적지는?
not_cancelled %>%
count(dest) %>% arrange(desc(n))# A tibble: 104 × 2
dest n
<chr> <int>
1 ATL 16837
2 ORD 16566
3 LAX 16026
4 BOS 15022
5 MCO 13967
6 CLT 13674
7 SFO 13173
8 FLL 11897
9 MIA 11593
10 DCA 9111
# ℹ 94 more rows
# ℹ Use `print(n = ...)` to see more rows위 코드를 실행하면 not_cancelled 데이터셋을 사용합니다. %>% 연산자를 사용하여 다음과 같은 작업들을 순차적으로 수행합니다:
- count(dest)를 사용하여 도착지(dest)별로 발생하는 횟수를 계산합니다.
- count() 함수는 주어진 변수의 고유한 값들과 해당 값들이 나타나는 횟수(n)를 반환합니다.
- arrange(desc(n))을 사용하여 발생하는 횟수(n) 기준으로 내림차순으로 정렬합니다.
→ 결과적으로 반환된 데이터프레임에는 도착지(dest)와 해당 도착지에서의 발생 횟수 (n)가 저장됩니다. 이렇게 생성된 데이터프레임은 도착지별로 빈도 정보와 관련된 요약 통계량을 포함하고 있습니다. 정렬 단계에서는 발생하는 횟수가 많은 순서대로 정렬되어 있으므로, 가장 많이 나타나는 도착지부터 나열됩니다 (내림차순)
가장 많은 비행을 한 비행기는?
not_cancelled %>%
count(tailnum, wt = distance)%>% arrange(desc(n))# A tibble: 4,037 × 2
tailnum n
<chr> <dbl>
1 N328AA 929090
2 N338AA 921172
3 N335AA 902271
4 N327AA 900482
5 N323AA 839468
6 N319AA 837924
7 N336AA 833136
8 N329AA 825826
9 N324AA 786159
10 N339AA 783648
# ℹ 4,027 more rows
# ℹ Use `print(n = ...)` to see more rowswt는 count() 함수의 인자 중 하나로, 가중치(weight)를 지정하는 역할을 합니다.
count() 함수는 주어진 변수들의 고유한 값들과 해당 값들이 나타나는 횟수를 계산하여 데이터프레임으로 반환합니다. 이때, wt 인자를 사용하여 가중치 값을 지정할 수 있습니다. 가중치는 각 관측치에 대해 적용되며, 해당 관측치의 중요도 또는 영향력을 반영하는 값입니다.
예를 들어, 위 코드에서 count(tailnum, wt = distance)은 항공기 번호(tailnum)별로 운항 거리(distance)를 가중치로 사용하여 발생하는 횟수를 계산합니다. 이 경우, 운항 거리가 더 긴 항공기일수록 해당 항공기의 발생 횟수에 더 큰 영향을 줄 수 있습니다. 따라서 발생 횟수(n) 계산 시 운항 거리(distance)가 가중치로 적용됩니다.
즉, wt 인자는 각 관측치에 대해 적용되어야 하는 가중치 값을 지정하는데 사용되며, 결과적으로 해당 가중치가 고려된 값을 기반으로 발생 횟수 등을 계산할 수 있게 해줍니다
5 시 이전에 출발하는 비행기는 몇대?
- sum(x > 10): 횟수
- mean(y == 0): 비율
not_cancelled %>%
group_by(year, month, day) %>%
summarise(n_early = sum(dep_time < 500))# A tibble: 365 × 4
# Groups: year, month [12]
year month day n_early
<int> <int> <int> <int>
1 2013 1 1 0
2 2013 1 2 3
3 2013 1 3 4
4 2013 1 4 3
5 2013 1 5 3
6 2013 1 6 2
7 2013 1 7 2
8 2013 1 8 1
9 2013 1 9 3
10 2013 1 10 3
# ℹ 355 more rows
# ℹ Use `print(n = ...)` to see more rows1 시간 이상 지연된 비행기 비율은?
not_cancelled %>%
group_by(year, month, day) %>%
summarise(hour_perc = mean(arr_delay > 60))# A tibble: 365 × 4
# Groups: year, month [12]
year month day hour_perc
<int> <int> <int> <dbl>
1 2013 1 1 0.0722
2 2013 1 2 0.0851
3 2013 1 3 0.0567
4 2013 1 4 0.0396
5 2013 1 5 0.0349
6 2013 1 6 0.0470
7 2013 1 7 0.0333
8 2013 1 8 0.0213
9 2013 1 9 0.0202
10 2013 1 10 0.0183
# ℹ 355 more rows
# ℹ Use `print(n = ...)` to see more rows여러 변수를 이용한 그룹 지정
daily <- group_by(flights, year, month, day)(per_day <- summarise(daily, flights = n()))# A tibble: 365 × 4
# Groups: year, month [12]
year month day flights
<int> <int> <int> <int>
1 2013 1 1 842
2 2013 1 2 943
3 2013 1 3 914
4 2013 1 4 915
5 2013 1 5 720
6 2013 1 6 832
7 2013 1 7 933
8 2013 1 8 899
9 2013 1 9 902
10 2013 1 10 932
# ℹ 355 more rows
# ℹ Use `print(n = ...)` to see more rows(per_month <- summarise(per_day, flights = sum(flights)))# A tibble: 12 × 3
# Groups: year [1]
year month flights
<int> <int> <int>
1 2013 1 27004
2 2013 2 24951
3 2013 3 28834
4 2013 4 28330
5 2013 5 28796
6 2013 6 28243
7 2013 7 29425
8 2013 8 29327
9 2013 9 27574
10 2013 10 28889
11 2013 11 27268
12 2013 12 28135(per_year <- summarise(per_month, flights = sum(flights)))# A tibble: 1 × 2
year flights
<int> <int>
1 2013 336776- 그룹 정보가 더이상 필요가 없을 때: ungroup()을 이용하여 그룹 해제:
daily %>%
ungroup() %>% # no longer grouped by date
summarise(flights = n()) # all flights# A tibble: 1 × 1
flights
<int>
1 336776각 그룹에서 최하위 찾기
- 상위10개 : desc 사용 / 각 그룹별 rank를 계산
flights %>%
group_by(year, month, day) %>%
filter(rank(desc(arr_delay)) <= 10)
# A tibble: 3,609 × 19
# Groups: year, month, day [365]
year month day dep_time sched_dep_time dep_delay
<int> <int> <int> <int> <int> <dbl>
1 2013 1 1 848 1835 853
2 2013 1 1 1815 1325 290
3 2013 1 1 1842 1422 260
4 2013 1 1 1938 1703 155
5 2013 1 1 1942 1705 157
6 2013 1 1 2006 1630 216
7 2013 1 1 2115 1700 255
8 2013 1 1 2205 1720 285
9 2013 1 1 2312 2000 192
10 2013 1 1 2343 1724 379
# ℹ 3,599 more rows
# ℹ 13 more variables: arr_time <int>,
# sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
# air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>
# ℹ Use `print(n = ...)` to see more rows위 코드를 실행하면 flights 데이터셋을 사용합니다. %>% 연산자를 사용하여 다음과 같은 작업들을 순차적으로 수행합니다:
- group_by(year, month, day)를 사용하여 연도(year), 월(month), 일(day)별로 그룹화합니다.
- filter() 함수를 사용하여 각 그룹에서 도착 지연 시간 (arr_delay)을 내림차순으로 정렬하고, 상위 10개의 관측치만 필터링합니다.
- desc(arr_delay)는 도착 지연 시간을 내림차순으로 정렬합니다.
- rank() 함수는 정렬된 값들의 순위를 계산합니다.
- <= 10 조건은 순위가 10 이하인 관측치들만 선택합니다.
→ 결과적으로 반환된 데이터프레임은 연도, 월, 일별로 그룹화되며 각 그룹에서 도착 지연 시간이 가장 큰 상위 10개의 관측치만 포함하고 있습니다. 이를 통해 가장 큰 도착 지연 시간을 가진 상위 10개의 이상치나 주요한 관측치 등에 초점을 맞출 수 있습니다.
기준 조건 이상의 그룹 찾기
popular_dests <- flights %>%group_by(dest) %>%
filter(n() > 365)
popular_dests# A tibble: 332,577 × 19
# Groups: dest [77]
year month day dep_time sched_dep_time dep_delay
<int> <int> <int> <int> <int> <dbl>
1 2013 1 1 517 515 2
2 2013 1 1 533 529 4
3 2013 1 1 542 540 2
4 2013 1 1 544 545 -1
5 2013 1 1 554 600 -6
6 2013 1 1 554 558 -4
7 2013 1 1 555 600 -5
8 2013 1 1 557 600 -3
9 2013 1 1 557 600 -3
10 2013 1 1 558 600 -2
# ℹ 332,567 more rows
# ℹ 13 more variables: arr_time <int>,
# sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
# air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>
# ℹ Use `print(n = ...)` to see more rows각 그룹마다 새로운 변수 생성하기
popular_dests %>%
filter(arr_delay > 0) %>%
mutate(prop_delay = arr_delay / sum(arr_delay)) %>%
select(year:day, dest, arr_delay, prop_delay)# A tibble: 131,106 × 6
# Groups: dest [77]
year month day dest arr_delay prop_delay
<int> <int> <int> <chr> <dbl> <dbl>
1 2013 1 1 IAH 11 0.000111
2 2013 1 1 IAH 20 0.000201
3 2013 1 1 MIA 33 0.000235
4 2013 1 1 ORD 12 0.0000424
5 2013 1 1 FLL 19 0.0000938
6 2013 1 1 ORD 8 0.0000283
7 2013 1 1 LAX 7 0.0000344
8 2013 1 1 DFW 31 0.000282
9 2013 1 1 ATL 12 0.0000400
10 2013 1 1 DTW 16 0.000116
# ℹ 131,096 more rows
# ℹ Use `print(n = ...)` to see more rows위 코드를 실행하면 popular_dests 데이터셋을 사용합니다. %>% 연산자를 사용하여 다음과 같은 작업들을 순차적으로 수행합니다:
- filter(arr_delay > 0)를 사용하여 도착 지연 시간이 양수인 경우만 필터링합니다.
- mutate(prop_delay = arr_delay / sum(arr_delay))를 사용하여 각 행에 대해 도착 지연 시간의 비율 (prop_delay)을 계산합니다.
- sum(arr_delays)는 전체 도착 지연 시간의 합계를 계산합니다.
- arr_delays / sum(arr_delays)는 각 행의 도착 지연 시간을 전체 합계로 나눈 비율을 계산합니다.
- select(year:day, dest, arr_delay, prop_dela)를 사용하여 연도(year), 월(month), 일(day), 도착지 (dest), 도착 지연 시간 (arr_delays) 및 지연 시간 비율 (prop_dela) 열만 선택합니다.
→결과적으로 반환된 데이터프레임은 필터링된 양수 값들에 대해 연도부터 일까지의 날짜 정보와 해당 날짜와 관련된 도착지 정보 그리고 그 날짜 및 해당 도착지에서의 도착 지연시간과 그에 대한 비율 정보가 포함되어 있습니다. 이렇게 생성된 데이터프레임은 양수인 경우의 도착 지연시간과 해당 날짜 및 목적지에 관한 추가적인 분석이나 요약 통계량 생성 등에 활용될 수 있습니다.