[Kaggle] Women's E-Commerce Clothing Reviews
1. Data
Women's E-Commerce Clothing Reviews (kaggle.com)
Women's E-Commerce Clothing Reviews
23,000 Customer Reviews and Ratings
www.kaggle.com
2. Code
## Calling libraries
!pip install textblob
!pip install cufflinks
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from textblob import TextBlob
from nltk import word_tokenize,pos_tag
from plotly.offline import init_notebook_mode, iplot
import plotly.figure_factory as ff
import cufflinks
cufflinks.go_offline()
cufflinks.set_config_file(world_readable=True, theme='pearl')
import plotly.graph_objs as go
import plotly
from plotly import tools
init_notebook_mode(connected=True)
import nltk
import re
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier,BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import cross_val_score,GridSearchCV,RandomizedSearchCV
from sklearn.feature_extraction.text import TfidfVectorizer as TV
from sklearn.model_selection import train_test_split,cross_val_score,KFold
from sklearn.naive_bayes import BernoulliNB
from sklearn.metrics import accuracy_score,roc_auc_score,roc_curve,confusion_matrix,classification_report,cohen_kappa_score
import warnings
warnings.filterwarnings("ignore")
## Reading Dataset
df = pd.read_csv("C:/Users/User/Documents/Womens Clothing E-Commerce Reviews.csv")
df.head()
1. 토픽 모델링 작업: 토픽을 추출은 어느 텍스트나 상관성이 없음. 다만 perplexity를 추출해서 몇 개의 토픽을 추출해야 하는지는 보여줘야 함
import pandas as pd
import numpy as np
import sklearn
import warnings
warnings.filterwarnings(action='ignore')dfprint(len(df))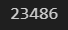
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(token_pattern="[\w']{3,}", stop_words='english',
max_features=2000, min_df=1, max_df=3)
review_cv = cv.fit_transform(df)from sklearn.decomposition import LatentDirichletAllocation
import numpy as np
np.set_printoptions(precision=3)
lda = LatentDirichletAllocation(n_components = 10, #추출할 topic의 수
max_iter=5,
topic_word_prior=0.1, doc_topic_prior=1.0,
learning_method='online',
n_jobs= -1, #사용 processor 수
random_state=0)
review_topics = lda.fit_transform(review_cv)
print('#shape of review_topics:', review_topics.shape)
print('#Sample of review_topics:', review_topics[0])
gross_topic_weights = np.mean(review_topics, axis=0)
print('#Sum of topic weights of documents:', gross_topic_weights)
print('#shape of topic word distribution:', lda.components_.shape)
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d: " % topic_idx, end='')
top_words = [feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]]
print(", ".join(top_words))
print()
print_top_words(lda, cv.get_feature_names_out(), 10)
import matplotlib.pyplot as plt
def show_perplexity(cv, start=10, end=30, max_iter=5, topic_word_prior=0.1, doc_topic_prior=1.0):
iter_num = []
per_value = []
for i in range(start, end + 1):
lda = LatentDirichletAllocation(n_components=i, max_iter=max_iter,
topic_word_prior=topic_word_prior,
doc_topic_prior=doc_topic_prior,
learning_method='batch', n_jobs=-1,
random_state=7)
lda.fit(cv)
iter_num.append(i)
pv = lda.perplexity(cv)
per_value.append(pv)
print(f'n_components: {i}, perplexity: {pv:0.3f}')
plt.plot(iter_num, per_value, 'g-')
plt.show()
return start + per_value.index(min(per_value))
print("n_components with minimum perplexity:", show_perplexity(review_cv, start=3, end=15))

lda = LatentDirichletAllocation(n_components = 5, #추출할 topic의 수를 지정
max_iter=20,
topic_word_prior= 0.1,
doc_topic_prior=1.0,
learning_method='batch',
n_jobs= -1,
random_state=22)
review_topics = lda.fit_transform(review_cv)
print_top_words(lda, cv.get_feature_names_out(), 10)
2. word2vec을 사용해서 유사한 단어군들 찾아보기
import gensim
import pandas as pd
import matplotlib.pyplot as plt
import urllib.request
from gensim.models.word2vec import Word2Vectrain_data = pd.read_csv("C:/Users/User/Documents/Womens Clothing E-Commerce Reviews.csv")
#상위 45개 출력
train_data.head(45)# Null값 존재 유무
print(train_data.isnull().values.any())
# Null 값이 존재하는 행 제거
train_data = train_data.dropna(how = 'any')
print(train_data.isnull().values.any()) # Null 값이 존재하는지 다시 확인
from konlpy.tag import Okt
from tqdm import tqdm
from konlpy.tag import Okt
from tqdm import tqdm
okt = Okt()
# 불용어 정의
stopwords = ['english']
# 형태소 분석기 OKT를 사용한 토큰화 작업 (다소 시간 소요)
okt = Okt()
tokenized_data = []
for sentence in tqdm(train_data['Review Text']):
tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_sentence)
# 리뷰 길이 분포 확인
print('리뷰의 최대 길이 :',max(len(review) for review in tokenized_data))
print('리뷰의 평균 길이 :',sum(map(len, tokenized_data))/len(tokenized_data))
plt.hist([len(review) for review in tokenized_data], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()

from gensim.models import Word2Vec
model = Word2Vec(sentences = tokenized_data, vector_size = 100, window = 5, min_count = 5, workers = 4, sg = 0)print(model.wv.most_similar("dresses"))[('tops', 0.8794119954109192), ('brands', 0.7533227205276489), ('clothes', 0.7516173124313354), ('jackets', 0.7252040505409241), ('tees', 0.7003142237663269), ('blouses', 0.693057119846344), ('maeve', 0.6928855180740356), ('shirts', 0.6709564924240112), ('styles', 0.6664469838142395), ('items', 0.6511412262916565)]
print(model.wv.most_similar("bottoms"))[('shorts', 0.7498459219932556), ('pilcro', 0.7449479103088379), ('skirts', 0.7439087629318237), ('paige', 0.7059122323989868), ('ag', 0.7000054121017456), ('stevie', 0.6911702156066895), ('jackets', 0.6882929801940918), ('tees', 0.674484133720398), ('capris', 0.6586064696311951), ('pants', 0.6580092906951904)]
print(model.wv.most_similar("tops"))[('dresses', 0.8794118165969849), ('clothes', 0.7406312823295593), ('brands', 0.7198451161384583), ('jackets', 0.7138069868087769), ('maeve', 0.7059479355812073), ('shirts', 0.6961106657981873), ('blouses', 0.6546631455421448), ('sweaters', 0.6483883261680603), ('brand', 0.6356804370880127), ('tees', 0.6254385113716125)]
model.wv.most_similar(positive=['jumpsuit','shirt'], topn=5)[('romper', 0.8606042265892029),
('blouse', 0.8558079600334167),
('vest', 0.8083049654960632),
('dress', 0.8011214137077332),
('suit', 0.7959854602813721)]
model.wv.most_similar(positive=['tracy','zipper'], topn=5)[('decorative', 0.7221032381057739),
('unraveled', 0.6814325451850891),
('coupon', 0.6754084825515747),
('major', 0.6737720966339111),
('glance', 0.6736555099487305)]
model.wv.most_similar(positive=['blouse','pullover'], topn=5)[('vest', 0.8327021598815918),
('sweater', 0.8079816102981567),
('swimsuit', 0.8002774119377136),
('coat', 0.7994661927223206),
('poncho', 0.7581604719161987)]
model.wv.similarity('sweater', 'coat')0.82533956
model.wv.similarity('shirt', 'bottoms')0.09428413
model.wv.most_similar(positive=['jumpsuit','bottoms'], negative=['outerwear'], topn=2)[('romper', 0.5721637010574341), ('brand', 0.5685563683509827)]
model.wv.doesnt_match("Tops shirt blouse top".split())'shirt'
model.wv.most_similar(positive=['shirt','blouse'],topn=5)[('top', 0.8652969002723694),
('skirt', 0.790992796421051),
('dress', 0.7808890342712402),
('sweater', 0.7731444239616394),
('vest', 0.766346275806427)]
3. doc2vec을 사용해서 문서내에서 같은 주제를 찾아내기
import pandas as pd
from konlpy.tag import Mecab
from gensim.models.doc2vec import TaggedDocument
from tqdm import tqdmdf = pd.read_csv("C:/Users/User/Documents/Womens Clothing E-Commerce Reviews.csv")
df = df.dropna()
dffrom konlpy.tag import Okt
from tqdm import tqdm
okt = Okt()
tagged_corpus_list = []
for index, row in tqdm(df.iterrows(), total=len(df)):
text = row['Review Text']
tag = row['Class Name']
words = okt.morphs(text)
tagged_corpus_list.append((words, tag))
print('문서의 수:', len(tagged_corpus_list))
tagged_corpus_list[0](['I',
'had',
'such',
'high',
'hopes',
'for',
'this',
'dress',
'and',
'really',
'wanted',
'it',
'to',
'work',
'for',
'me',
'.',
'i',
'initially',
'ordered',
'the',
'petite',
'small',
'(',
'my',
'usual',
'size',
')',
'but',
'i',
'found',
'this',
'to',
'be',
'outrageously',
'small',
'.',
'so',
'small',
'in',
'fact',
'that',
'i',
'could',
'not',
'zip',
'it',
'up',
'!',
'i',
'reordered',
'it',
'in',
'petite',
'medium',
',',
'which',
'was',
'just',
'ok',
'.',
'overall',
',',
'the',
'top',
'half',
'was',
'comfortable',
'and',
'fit',
'nicely',
',',
'but',
'the',
'bottom',
'half',
'had',
'a',
'very',
'tight',
'under',
'layer',
'and',
'several',
'somewhat',
'cheap',
'(',
'net',
')',
'over',
'layers',
'.',
'imo',
',',
'a',
'major',
'design',
'flaw',
'was',
'the',
'net',
'over',
'layer',
'sewn',
'directly',
'into',
'the',
'zipper',
'-',
'it',
'c'],
'Dresses')
from gensim.models import doc2vecfrom gensim.models import doc2vec
model = doc2vec.Doc2Vec(vector_size=300, alpha=0.025, min_alpha=0.025, workers=8, window=8)
tagged_corpus_list = []
for index, row in tqdm(df.iterrows(), total=len(df)):
text = row['Review Text']
tag = row['Class Name']
words = okt.morphs(text)
tagged_corpus_list.append(doc2vec.TaggedDocument(words=words, tags=[tag]))
model.build_vocab(tagged_corpus_list)
model.train(tagged_corpus_list, total_examples=model.corpus_count, epochs=50)
model.save('clothe_review.doc2vec')
import warnings
warnings.filterwarnings(action='ignore')similar_doc = model.docvecs.most_similar('Dresses')
print(similar_doc)[('Chemises', 0.5459057092666626), ('Skirts', 0.41693100333213806), ('Trend', 0.4021424651145935), ('Blouses', 0.3639832139015198), ('Fine gauge', 0.34717682003974915), ('Jackets', 0.3458446264266968), ('Lounge', 0.33954375982284546), ('Sweaters', 0.3298146426677704), ('Knits', 0.3109866678714752), ('Swim', 0.3005999028682709)]
similar_doc = model.docvecs.most_similar('Knits')
print(similar_doc)[('Blouses', 0.6003979444503784), ('Fine gauge', 0.5172967910766602), ('Sweaters', 0.4864758253097534), ('Chemises', 0.46471041440963745), ('Casual bottoms', 0.4309837818145752), ('Layering', 0.4127601683139801), ('Lounge', 0.39144495129585266), ('Jackets', 0.3723991811275482), ('Intimates', 0.33433014154434204), ('Outerwear', 0.31811270117759705)]
similar_doc = model.docvecs.most_similar('Lounge')
print(similar_doc)[('Pants', 0.46661004424095154), ('Sleep', 0.4458904564380646), ('Chemises', 0.4173845052719116), ('Legwear', 0.391911119222641), ('Shorts', 0.3916783630847931), ('Knits', 0.39144495129585266), ('Casual bottoms', 0.38708069920539856), ('Intimates', 0.3856559097766876), ('Swim', 0.38311997056007385), ('Layering', 0.3799075782299042)]