[1장] 머신러닝 개념 및 넘파이_파이썬 머신러닝 완벽가이드
1.머신러닝이란?
- 데이터를 기반으로 패턴을 학습하고 결과를 추론하는 알고리즘 기법
- 특징: 데이터 마이닝, 영상 인식, 음성 인식, 자연어 처리에 적용
2. 머신러닝의 필요성
- 복잡한 문제를 데이터를 기반으로 숨겨진 패턴을 인지하여 해결함
- 데이터를 기반으로 통계적 신뢰도를 강화하고 예측 오류를 최소화하기 위한 다양한 수학적 기법을 적용해 데이터 내의 패턴을 스스로 인지하고 신뢰도 있는 예측 결과를 도출함
3. 머신러닝의 분류
- 지도학습: 명확한 결정값이 주어진 데이터를 학습
ex. 분류, 회귀, 추천시스템, 시각/음성 인지, 텍스트 분석, NLP
- 비지도학습: 결정값이 주어지지 않는 데이터를 학습
ex. 군집화(클러스터링), 차원 축소, 강화학습
4. 머신러닝의 단점
- 데이터에 너무 의존적임
- 개발자가 직접 만든 코드보다 정확도가 오히려 떨어질 수 있음
5. R과 파이썬의 차이
1) R: 통계 전용 프로그램 언어로 전통적인 통계 및 마이닝 패키지의 고비용으로 고민하던 통계 전문가들이 개선하고자 만든 언어
2) 파이썬: 직관적인 문법과 객체지향과 함수형 프로그래밍 모두를 포괄하는 유연한 프로그램 아키텍처, 다양한 라이브러리 등의 큰 강점을 가지면서 프로그래밍 세계에서 가장 많이 사용하는 언어 중 하나
6. 파이썬 머신러닝 생태계를 구성하는 주요 패키지
- 머신러닝 패키지: 싸이킷런
- 배열/선형대수/통계 패키지: Numpy, Scipy
- 데이터 핸들링: pandas
- 시각화: matplotilb, seaborn
- 대화형 파이썬 툴: jupyter notebook
1. 넘파이 ndarray : N차원 배열 객체
→ array() 함수로 생성하여 파이썬 리스트 또는 ndarray 입력
→ 정수, 실수, 문자열 입력 가능(단, 같은 데이터 타입만 가능)
import numpy as np
array1 = np.array([1,2,3]) → 1차원 배열, shape(3,)
array2 = np.array([[1,2,3],[2,3,4]]) → 2차원 배열, shape(2,3) : 행2줄, 열3줄

2. ndarray 타입
- ndarray내의 데이터 값은 숫자값, 문자열값, 불값 모두 가능
- 숫자형의 경우 int형, unsigned int형, float형, complex 타입 제공
- ndarray 내의 데이터 타입은 그 연산의 특성상 같은 데이터 타입만 가능
(int형과 float형이 같은 ndarray 객체에 있을 수 없음)
- ndarray.dtype으로 데이터 타입 확인 가능
- DataFrame을 ndarray로 변환: DataFrame 객체의 values 속성을 이용하여 ndarray 변환
→ DF.values 이용
1) 넘파이 ndarray, 리스트, 딕셔너리를 DataFrame으로 변환하기
import numpy as np
col_name1=['col1']
list1 = [1, 2, 3]
array1 = np.array(list1)
print('array1 shape:', array1.shape )
df_list1 = pd.DataFrame(list1, columns=col_name1)
print('1차원 리스트로 만든 DataFrame:\n', df_list1)
df_array1 = pd.DataFrame(array1, columns=col_name1)
print('1차원 ndarray로 만든 DataFrame:\n', df_array1)
array1 shape: (3,)
1차원 리스트로 만든 DataFrame:
col1
0 1
1 2
2 3
1차원 ndarray로 만든 DataFrame:
col1
0 1
1 2
2 3
2) DataFrame의 칼럼 데이터 세트 생성과 수정
titanic_df['Age_by_10'] = titanic_df['Age']*10
titanic_df['Family_No'] = titanic_df['SibSp'] + titanic_df['Parch']+1
titanic_df.head(3)

3) DataFrame 데이터 삭제
#axis=1은 컬럼 방향성(가로), axis=0은 로우 방향성(세로)
# inplace=True : 원 데이터도 적용, inplace=False : 원본 데이터는 적용x
titanic_df = titanic_df.drop('Fare', axis=1, inplace=False)
titanic_df.head()
3. astype() 을 이용한 타입 변환
apple = [1.0, 2.0]
apple = apple.astype('float')
4. 넘파이 ndarray의 axis축

5. ndarray의 차원과 크기를 변경하는 reshape()
- reshape()은 ndarray를 특정 차원 및 형태로 변환

- reshape(-1,5)와 같이 인자에 -1을 부여하면 -1에 해당하는 axis의 크기는 가변적이되어 -1이 아닌 인자값에 해당하는 zix크기는 인자값으로 고정하여 ndarray의 shape를 변환

6. ndarray의 데이터 세트 선택- 인덱싱(indexing)
- 특정 위치의 단일값 추출: 원하는 위치의 인덱스 값을 지정하며 해당 위치의 데이터를 변환
- 슬라이싱 slicing: 연속된 인덱스상의 ndarray를 추출하는 방식
- 팬시 인덱싱 fancy indexing: 일정한 인덱싱 집합을 리스트 또는 ndarray 형태로 지정해 해당 위치에 있는 ndarray를 변환
- 불린 인덱싱 boolean indexing: 인덱싱 모두 사용할 필요없이 조건식을 []안에 기입하여 간편하게 필터링 수행
7. 단일 값 추출
1) 1차원 ndarray

2) 2차원 ndarray

3) 슬라이싱: 1차원 ndarray

4) 슬라이싱: 2차원 ndarray

5) 팬시 인덱싱: 1차원 ndarray
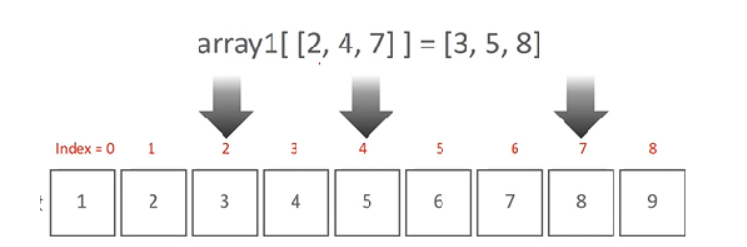
6) 팬시 인덱싱: 2차원 ndarray

8. Pclass와 Name으로 내림차순 정렬
- ascending=False 내림차순
- ascending=True 오름차순
titanic_sorted = titanic_df.sort_values(by=['Pclass', 'Name'], ascending=False) #내림차순 정렬
titanic_sorted.head(3)
9. 특정 컬럼들로 aggregation 수행
titanic_df[['Age', 'Fare']].mean() #평균값
Age 29.699118
Fare 32.204208
dtype: float64
titanic_df[['Age', 'Fare']].sum()
Age 21205.1700
Fare 28693.9493
dtype: float64
titanic_df[['Age', 'Fare']].count()
Age 714
Fare 891
dtype: int64
- groupby() 이용하기 groupby()내에 인자로 by를 Group by 하고자 하는 컬럼을 입력. 여러개의 컬럼으로 Group by 하고자 하면 []내에 컬럼명을 입력 DataFrame에 groupby()를 호출하면 DataFrameGroupBy 객체를 반환
titanic_groupby[['Age', 'Fare']]
* 파이썬 머신러닝 완벽가이드_인프런 강의