Machine Learning
사이킷런 의사결정나무 알고리즘 및 당뇨병 데이터셋
뉴욕킴
2024. 1. 16. 20:51
사이킷런 의사결정나무 알고리즘
Supervised learning의 classification 기법
- 새로 들어온 고객이 물건을 구매할지, 구매하지 않을지를 분류
- 1.10. Decision Trees — scikit-learn 1.3.2 documentation
1.10. Decision Trees
Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning s...
scikit-learn.org
- tree 패키지 불러오기
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]- 의사결정 트리 분류 (DecisionTreeClassifier)
>>> clf = tree.DecisionTreeClassifier()
>>> clf
- fit 함수를 통해 모델 학습 및 저장
clf = clf.fit(X, Y)
clf
- predict 함수는 정답을 0,1 중 하나로만 나타냄
clf.predict([[2., 2.]])
- predict_proba 함수를 사용하여 값이 비율로 출력
clf.predict_proba([[2., 2.]])>>> from sklearn.datasets import load_iris
>>> from sklearn import tree
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, y)- iris.data, iris.target을 X,y로 바꾸어 시각화 진
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 10))
t = tree.plot_tree(clf.fit(X, y))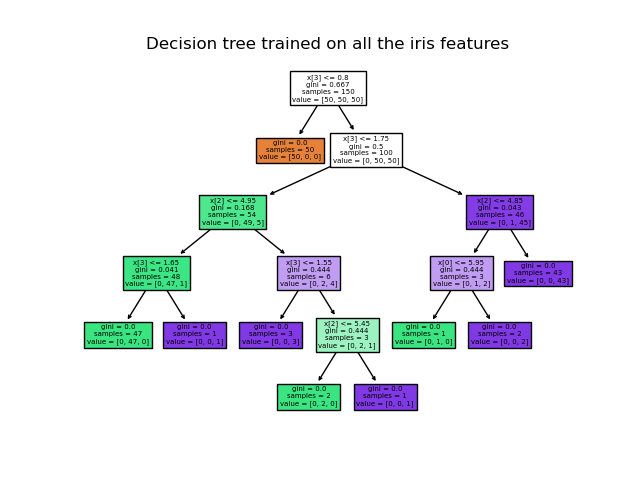
당뇨병 데이터셋
Pima Indians Diabetes Database (kaggle.com)
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com
Data 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
- 라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
- 데이터셋 로드
df=pd.read_csv('data/diabetes.csv')
df.shapedf.head()
- 학습, 예측 데이터셋 나누기
split_count = int(df.shape[0] * 0.8)
split_count
train = df[:split_count].copy()
train.shape
test=df[split_count:].copy()
test.shape
- 학습, 예측에 사용할 컬럼 지정
feature_names = train.columns[:-1].tolist()
feature_names
- 정답 컬럼 지정
label_name = train.columns[-1]
label_name
- 학습, 예측 데이터셋 만들기
X_train = train[feature_names]
print(X_train.shape)
X_train.head()y_train = train[label_name]
print(y_train.shape)
y_train.head()
- 예측에 사용할 데이터셋 만들기
X=test = test[feature_names]
pring(X_test.shape)
X_test.head()
y_test = test[label_name]
print(y_test.shape)
y_test.head()