2wk_Object Recognition (객체 인식), R-CNN, Fast R-CNN
Object Recognition (객체 인식)
- 컴퓨터비전(Computer vision), 영상처리(image processing)와 관계가 깊은 컴퓨터 기술
- Recognition: Object가 어떤 것인지 구분
- Object Detection: Recognition보다 더 작은 범위로써 Object의 존재 유무만 판단

Proposal-based models
• Faster R-CNN (NIPS 2015)
• R-FCN (NIPS 2016
Proposal-free models → 한번에 예측
• YOLO (CVPR 2016)
• SSD (ECCV 2016)
R-CNN (2014)

- R-CNN은 이미지에서 Bounding Box를 뽑아내고 각 Bounding Box를 CNN으로 Classification
- ROI를 뽑아 CNN에 각 집어넣는다. ROI는 약 2,000개 정도 뽑기 때문에 속도가 느리다는 단점이 있다.
- 뽑힌 ROI의 미세조정을 위한 Bounding Box regression을 위한 모델도 포함되어 있다.
- CNN의 input size는 정해져 있기 때문에 ROI들을 같은 크기로 Warping해주고 모델에 집어 넣는다.
- 출력은 CNN의 마지막 feature map을 SVM을 이용하여 Classification 한다. (성능이 좋기때문, 보통 fully connected layer + softmax)

→ 한 이미지당 2,000개를 뽑아 물체를 인식
→ Classification (분류)
→ Person? Yes
Fast R-CNN (2015) : 속도가 10배 빨라짐

- RoI 추출시 R-CNN과 마찬가지로 Selective Search로 뽑아냄
- R-CNN과 다르게 CNN에 넣을 때 Warping하지 않고 그대로 넣는다.
- 핵심은 RoI feature vector 부분이다. Conv feature map의 마지막 부분에서 RoI pooling만 해서 RoI부분만 추출하여 Fully Connected Layer로 넣는다. 그리고 최종적으로 물체에 대한 classification과 Bounding box regression을 진행한다.

→ 쿨링이 다르게 진행
- 기존에는 이미지에서 뽑아냈지만, Faster R-CNN은 물체가 있을만한 영역을 잡아주고

객체 탐지에서 앵커 박스의 기준 이해하기
→ 객체 탐지는 컴퓨터 비전 분야에서 중요한 역할을 하며, 이 과정에서 '앵커 박스(anchor boxes)'는 중요한 요소입니다. 앵커 박스란, 모델이 객체를 탐지할 때 사용하는 미리 정의된 박스를 말합니다. 여기에는 긍정 앵커, 부정 앵커, 무시 앵커 등이 있으며, 각각의 기준은 IoU(Intersection over Union)를 통해 결정됩니다. 여기서 IoU란, 예측된 바운딩 박스와 실제 바운딩 박스가 얼마나 겹치는지를 나타내는 지표입니다.
1. 긍정 앵커
최고 IoU 겹침: 객체의 실제 위치를 가장 잘 예측하는 앵커. 즉, 예측된 박스가 실제 박스와 가장 많이 겹칠 때 긍정적으로 평가됩니다.
IoU가 0.7 이상: 어떤 실제 박스와도 0.7 이상으로 겹치는 앵커 박스는 긍정 앵커로 분류됩니다. 이는 모델이 해당 영역에서 객체를 잘 탐지하고 있다고 판단할 수 있음을 의미합니다.
2. 부정 앵커
모든 실제 박스와 0.3 미만 겹침: 실제 박스와의 IoU가 0.3 미만인 앵커는 부정 앵커로 간주됩니다. 이는 해당 박스가 객체가 없는 배경 영역을 나타낸다고 볼 수 있습니다.
3. 무시 앵커
긍정 및 부정 앵커가 아닌 경우: IoU가 0.3과 0.7 사이인 앵커는 트레이닝 과정에서 고려하지 않습니다. 이러한 앵커는 모델에게 명확한 정보를 주지 못하기 때문입니다.
위의 기준을 통해 명확하게 객체를 인식하고 분류하는 것이 객체 탐지 모델의 궁극적인 목표입니다. 앵커 박스를 효과적으로 활용함으로써, 모델은 다양한 크기와 형태의 객체를 정확하게 탐지할 수 있게 됩니다. ☺️
R-FCN (2016)

→ 결과를 뽑아내고 쿨링을 진행하는 방법으로 속도가 더 빨라짐
→ Fast/Faster R-CNN 모델에 비해 더 낮은 계산 비용과 더 높은 속도를 제공
YOLO (2016)
- You Only Look Once: Unified, Real-Time Object Detection"이라는 제목으로 소개된 딥러닝 기반의 객체 탐지 방법입니다. 이 방법은 기존의 객체 탐지 방식과 큰 차이점을 가지며, 특히 실시간 처리에 초점을 맞추고 있다.

- 실시간 처리: YOLO는 한 번의 평가(evaluation)로 전체 이미지에서 객체의 바운딩 박스와 클래스 확률을 직접 예측합니다. 이는 처리 속도를 크게 향상시킵니다.
- 통합된 프레임워크: 객체 탐지를 하나의 회귀 문제로 다루며, 다수의 분리된 모델 대신 단일 신경망을 사용하여 객체의 위치와 분류를 동시에 예측합니다.
- 단순성: YOLO는 매우 단순한 구조를 가지고 있어 구현과 훈련이 용이합니다. 하나의 네트워크만으로 전체 이미지를 평가하고 결과를 얻을 수 있기 때문에 복잡성이 줄어듭니다.
- 배경 오류 감소: YOLO는 전체 이미지를 보고 객체를 예측하기 때문에 다른 방법들에 비해 배경 오류(잘못된 객체 탐지)가 적습니다.
SSD (2016): Comparison With YOLO
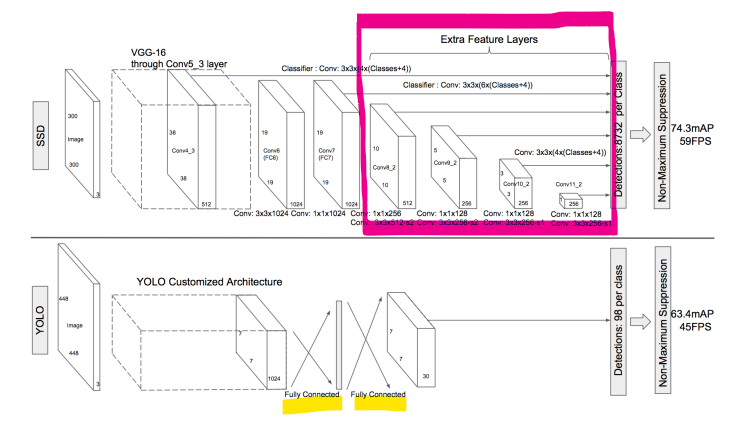
SSD (Single Shot MultiBox Detector) 2016: YOLO와의 비교
SSD와 YOLO는 둘 다 2016년에 대중의 주목을 끈 객체 탐지 모델입니다. 이 둘은 실시간 객체 탐지에 있어서 획기적인 기여를 했지만, 각기 다른 방식으로 이 문제를 접근합니다.
SSD와 YOLO의 주요 차이점
# 구조: SSD는 다양한 크기의 특성 맵에서 직접 객체를 탐지하여 다양한 규모의 객체를 효과적으로 처리할 수 있습니다. 반면, YOLO는 단일 특성 맵을 사용하여 객체를 탐지합니다.
# 성능: SSD는 작은 객체를 탐지하는 데 있어서 YOLO보다 상대적으로 우수한 성능을 보입니다. 이는 SSD가 다양한 해상도의 특성 맵을 활용하기 때문입니다.
# 속도: YOLO는 SSD에 비해 속도 면에서 우위를 가질 수 있습니다. YOLO는 전체 이미지를 한 번에 처리하는 반면, SSD는 여러 크기의 특성 맵에서 객체를 탐지하므로 계산량이 더 많을 수 있습니다.
SSD의 강점
# 다양한 크기의 객체 탐지: SSD는 다양한 크기의 특성 맵을 사용하여 작은 객체부터 큰 객체까지 다양한 크기의 객체를 효과적으로 탐지할 수 있습니다.
# 정확도: SSD 모델은 작은 객체의 탐지에 있어 특히 뛰어난 정확도를 보입니다. 이는 실제 세계의 객체 탐지 시나리오에서 매우 유용합니다.
YOLO의 강점
# 속도: 실시간 처리에 매우 적합하며, 비디오 스트림이나 카메라 피드에서 객체를 탐지하는 데 사용됩니다.
# 단순성: YOLO는 구조가 단순하여 배우기 쉽고 구현하기도 쉽습니다.
SSD와 YOLO 둘 다 객체 탐지 분야에 크게 기여했으며, 각각의 장단점을 가지고 있습니다. 사용자의 필요에 따라, 더 높은 속도를 요구하는 경우 YOLO를, 다양한 크기의 객체를 정확하게 탐지해야 하는 경우 SSD를 선택할 수 있습니다.
참고자료
01. Object Detection 이란? · GitBook (deepbaksuvision.github.io)
01. Object Detection 이란? · GitBook
No results matching ""
deepbaksuvision.github.io
[논문 리뷰] R-CNN/Fast R-CNN/Faster R-CNN : 네이버 블로그 (naver.com)
[논문 리뷰] R-CNN/Fast R-CNN/Faster R-CNN
Paper information - year : 2015 - author : Shaoqing Ren, Kaiming He, Ross Girshick, Jian Su...
blog.naver.com