"7wk_Convolutional Neural Networks(구조 파악)
Convolutional Neural Networks
딥러닝은 무엇인가?
- 신경망에서 히든레이어를 2개 이상 쓴 것
- 딥러닝은 히든 레이어를 두 개 이상 사용하는 신경망의 한 형태입니다. 현실에서는 여러 개의 히든 레이어를 사용합니다.
- 딥러닝이 성공하는 이유는 GPU와 같은 하드웨어의 발전, 빅 데이터의 확산, 그리고 여러 소프트웨어 기술의 발전 때문입니다. 여기에는 ReLU 활성화 함수, 드롭아웃 정규화, Adam 최적화 알고리즘 등이 포함됩니다.
합성곱 신경망(CNN, Convolutional Neural Networks)
- CNN은 1989년 LeCun에 의해 제안된 신경망의 특수한 형태로, 그리드 형태의 데이터 처리에 최적화되어 있습니다. 예를 들어, 이미지(2D 그리드)나 시계열 데이터(1D 그리드) 처리에 사용됩니다.
합성곱 연산(Convolutional Operation) ★ 시험 ------------ ------------ ------------ ------------ ------------ ------------ ------------
- 합성곱 연산은 특수한 형태의 선형 연산으로, 하나 이상의 합성곱 레이어를 포함하는 신경망을 CNN이라고 합니다.
- 합성곱 연산의 주요 동기는 공간 데이터 처리, 희소 연결, 매개변수 공유 등입니다.

이 이미지는 2D 합성곱 연산의 예를 보여줍니다. 여기에는 4x4 크기의 입력 데이터와 2x2 크기의 필터가 있으며, 그 결과로 3x3 크기의 출력 데이터가 생성됩니다.
합성곱 연산은 다음과 같이 수행됩니다:
입력 데이터는 4x4 크기의 단일 채널 그리드입니다(예: 흑백 이미지의 한 부분).
필터는 2x2 크기의 그리드로, 입력 데이터에 적용됩니다. 이 예에서 필터는 [[1, 0], [0, 1]]의 값을 가집니다.
필터를 입력 데이터의 각 위치에 적용하여, 필터와 해당 위치의 입력 데이터의 요소별 곱을 계산하고, 그 합을 출력 데이터의 해당 위치에 저장합니다.
이 연산은 필터가 입력 데이터의 가능한 모든 위치에 적용될 때까지 계속됩니다. 필터가 이동하면서 계산된 합은 출력 데이터의 다른 위치에 저장됩니다.
이미지에서 빨간색으로 강조된 부분은 현재 필터가 적용되는 입력 데이터의 위치를 나타냅니다. 이 위치에서의 연산 결과가 출력 데이터의 상응하는 셀에 저장됩니다. 이 경우, 출력 데이터의 첫 번째 셀은 값 '2'를 가지며, 이는 필터를 첫 번째 위치에 적용했을 때의 계산 결과입니다.
두 가지 주요 개념인 **희소 연결(sparse connection)**과 **매개변수 공유(parameter sharing)**가 이 연산에 적용됩니다. 희소 연결은 각 출력값이 입력 데이터의 작은 지역에만 연결되어 있음을 의미하며, 매개변수 공유는 동일한 필터(매개변수)가 입력 데이터 전체에 걸쳐 재사용된다는 것을 의미합니다. 이러한 특성은 합성곱 신경망이 이미지와 같은 고차원 데이터에서 유용한 특징을 효율적으로 학습할 수 있게 합니다.
이 이미지에는 합성곱 연산의 예시가 나타나 있습니다. 4x4x3 크기의 입력 데이터(3차원 텐서, 보통 이미지의 가로x세로x색상 채널)와 2x2x3 크기의 필터(합성곱 커널)가 사용되었고, 결과로 2x2x1 크기의 출력이 생성되었습니다.
합성곱 연산은 다음 단계로 진행됩니다:
입력 데이터의 각 채널에 대해 필터의 동일한 채널이 적용됩니다. 이 예에서는 입력 데이터의 채널 수(3)와 필터의 채널 수가 같기 때문에, 각 입력 데이터 채널에 대해 필터의 해당 채널이 매핑됩니다.
필터를 입력 데이터의 왼쪽 상단 모서리에 놓고, 요소별 곱셈을 수행합니다. 이후, 모든 곱셈 결과를 더하여 출력 데이터의 첫 번째 값(이 예시에서는 4)을 얻습니다.
필터를 오른쪽으로 한 칸 이동시키고, 동일한 요소별 곱셈과 합산 과정을 반복하여 출력 데이터의 두 번째 값(이 예시에서는 3)을 계산합니다.
필터를 아래로 한 칸 내리고 같은 과정을 반복하여 나머지 출력 값을 계산합니다.
최종적으로, 필터가 전체 입력 데이터 위를 이동하면서 요소별 곱셈과 합을 통해 결과적으로 2x2x1 크기의 출력을 생성합니다. 이 과정을 통해 입력 이미지의 특징을 감지하고 이를 기반으로 새로운 특징 맵을 생성합니다.
이 이미지에서 빨간색, 파란색, 녹색 박스는 필터가 입력 데이터 위에서 어떻게 이동하는지를 보여줍니다. 각각의 박스는 필터가 적용되는 입력 데이터의 다른 영역을 나타내며, 출력은 필터가 이 영역들 위를 이동하며 생성된 값들입니다.
합성곱 연산의 특징
합성곱 연산은 기본적으로 입력 데이터의 로컬 패치(local patches)에 필터를 적용하고, 이를 슬라이딩 윈도우 방식으로 전체 데이터에 적용합니다. 이 과정에서 데이터의 공간적 계층을 유지하면서 특징을 추출할 수 있습니다.
- 희소 연결(Sparse Connectivity)
- 각 뉴런은 입력 데이터의 일부 영역에만 연결되어 있습니다. 이는 연산 효율성을 높이고, 필요없는 데이터 연결을 최소화합니다. → 듬성듬성
- 매개변수 공유(Parameter Sharing)
- 같은 필터를 전체 이미지에 걸쳐 사용함으로써, 학습해야 할 매개변수의 수를 대폭 줄입니다. 이는 모델이 더 빠르게 학습하고, 더 적은 데이터로도 일반화 성능을 유지할 수 있게 도와줍니다. → 공유
- 등변성 특성(Translation Invariance)
- 이미지 내 객체의 위치가 달라도 같은 필터를 통해 유사한 특징을 추출할 수 있습니다. 이는 모델이 객체의 위치 변화에 강건하게 만들어 줍니다.
합성곱 신경망(CNN)에서 정규화(regularization) ★ 시험
- 정규화(Regularization): 모델이 학습 데이터에 과적합(overfit)되는 것을 방지하기 위해 사용되는 기술입니다. 과적합은 모델이 학습 데이터의 노이즈까지 학습해버려 새로운 데이터에 잘 일반화하지 못하는 현상을 말합니다.
- Dropout Regularization: 정규화의 한 형태로, 신경망의 특정 연결을 무작위로 '끊어서'(즉, 일시적으로 제거하여) 모델이 특정 노드나 경로에 과도하게 의존하는 것을 방지합니다.
- 희소 연결(Sparse Connection): CNN에서는 입력 이미지의 모든 픽셀을 모든 뉴런에 연결하지 않습니다. 대신, 작은 필터를 사용해 입력 데이터의 작은 지역과만 연결을 맺으므로, 연결이 희소해집니다. 이는 데이터의 중요한 특징을 캡처하는 데 도움을 주면서도 계산 효율성을 높입니다.
- 매개변수 공유(Parameter Sharing): CNN에서 필터의 가중치는 이미지 전체에서 공유됩니다. 즉, 한 필터가 이미지의 한 영역에서 학습한 가중치를 다른 모든 영역에 적용하여 매개변수의 수를 줄이고 계산 효율성을 높입니다.
이제 주어진 설명으로 돌아가면:
- Dense CNN은 가상의 용어로, 일반적인 다층 퍼셉트론(MLP)처럼 모든 연결이 완전하게 연결된 CNN을 가리키는 것 같습니다. 하지만 실제로 CNN은 희소 연결 구조를 가지고 있습니다.
- CNN에서는 Dropout을 사용할 수 없다는 것이 아니라, Dropout이 무작위로 연결을 끊는 방식과는 달리, CNN은 구조적으로 이미 희소 연결을 갖고 있기 때문에 연결을 끊는 방식이 다르다는 뜻입니다.
- CNN이 픽셀의 일부만 보고 전체를 보지 않는다는 부분은, 필터가 이미지의 전체를 한 번에 볼 수 없고, 작은 영역(예: 3x3 또는 5x5)만 본다는 것을 의미합니다.
- 마지막으로, CNN이 매개변수 공유로 인해 강력한 정규화 효과를 가지고 있다고 설명하는 것은, 같은 필터(매개변수)를 이미지의 다양한 위치에 적용함으로써, 모델이 과도하게 복잡해지는 것을 막고, 이미지 내의 공간적 패턴을 더 효과적으로 학습한다는 것을 강조합니다.
요약하자면, CNN은 이미지와 같은 공간 데이터에서 중요한 특징을 효율적으로 추출하고 일반화할 수 있도록 설계된 신경망 아키텍처로, 그 과정에서 자연스럽게 정규화 효과를 가집니다.
연산★ 시험

이 이미지에는 3차원 입력 데이터(4x4x3)에 3차원 필터(2x2x3)를 적용한 합성곱 연산의 예시가 나와 있습니다. 이 연산을 통해 2x2x1 크기의 출력이 생성됩니다.
합성곱 연산에서 출력의 한 원소를 계산하는 방법은 다음과 같습니다:
필터의 각 원소를 입력 데이터의 해당 위치에 있는 원소와 곱합니다.
이러한 모든 곱셈 결과를 더합니다.
결과적으로 얻은 합계가 출력의 한 원소가 됩니다.
입력 데이터는 각각의 색상 채널(RGB)을 나타내는 3개의 4x4 매트릭스로 구성되어 있습니다. 필터는 각 채널에 대해 2x2 크기의 매트릭스로 구성되어 있고, 각 필터는 해당 채널에 적용됩니다. 출력은 필터를 적용한 후의 결과물입니다.
출력의 첫 번째 원소(4)를 계산하기 위해 다음 단계를 따릅니다:
입력 데이터의 첫 번째 채널의 상단 왼쪽 2x2 부분을 필터의 첫 번째 채널과 요소별 곱셈을 수행합니다.
같은 방식으로 입력 데이터의 두 번째 및 세 번째 채널에 대해서도 수행합니다.
이 세 결과를 모두 더합니다.
예를 들어, 입력 데이터의 첫 번째 채널에서 첫 번째 원소(1)과 필터의 첫 번째 채널에서 첫 번째 원소(1)를 곱하고, 나머지 원소들도 같은 방식으로 계산합니다. 각 채널에서 나온 결과들을 모두 더해서 최종 값을 얻습니다.
특정 숫자 값으로 예를 들어보면:
1차원:
(1 * 1) + (1 * 0) + (0 * 0) + (1 * 1) = 1 + 0 + 0 + 1 = 2
2차원:
(0 * 1) + (0 * 0) + (1 * 0) + (1 * 1) = 0 + 0 + 0 + 1 = 1
3차원:
(0 * 1) + (1 * 0) + (1 * 0) + (1 * 1) = 0 + 0 + 0 + 1 = 1
최종 합계: 2 + 1 + 1 = 4
따라서 첫 번째 출력 원소는 4가 됩니다. 이러한 계산 방식은 CNN에서 특징 맵(feature map)을 생성하기 위해 전체 입력 데이터에 대해 반복적으로 수행됩니다.→ 5-1 48분


------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
합성곱 연산 예제
- 입력 데이터가 4x4 그리드이고, 2x2 필터를 사용하는 예를 들면, 출력은 3x3 그리드가 됩니다.
- 합성곱 연산은 필터를 입력 데이터에 적용하여 각 위치에서 필터와 입력 데이터의 요소별 곱셈 결과의 합을 출력 데이터에 기록합니다.
합성곱 연산은 입력 데이터와 필터 간의 요소별 곱셈 후, 이를 모두 합산하여 출력 데이터를 생성합니다. 예를 들어, 4x4의 이미지에 2x2 필터를 적용하면, 필터를 이미지 전체에 순차적으로 적용하여 3x3 크기의 새로운 특징 맵(feature map)을 생성합니다.
다채널 합성곱 연산
- RGB 이미지와 같이 여러 채널을 가진 입력 데이터의 경우, 각 채널에 대해 별도의 필터를 적용하고 그 결과를 합칩니다.
- 예를 들어, RGB 각 채널에 5x5 크기의 필터를 적용한 후, 모든 채널의 출력을 합산하여 최종 출력을 만듭니다. 이는 다채널 입력에서도 효과적으로 특징을 추출할 수 있도록 해줍니다.
다채널 입력에 대한 합성곱 연산
- 멀티채널 입력(예: RGB 이미지)을 처리할 때는 각 채널에 대해 별도의 필터를 적용하고, 결과를 합산하여 최종 출력을 생성합니다.
- 예를 들어, 3채널 입력 데이터에 대해 각 채널마다 5x5 크기의 필터를 적용할 경우, 최종 결과는 이 필터들의 결과를 합산한 것입니다.
합성곱 레이어의 층적 구조
합성곱 신경망은 일반적으로 여러 합성곱 레이어를 쌓아서 복잡한 특징을 계층적으로 학습합니다. 각 레이어는 점점 더 추상적인 정보를 추출하여, 최종적으로는 객체의 식별 같은 고수준 작업을 수행할 수 있는 특징으로 변환됩니다.
이러한 합성곱 신경망은 시각 인식, 이미지 처리 등 다양한 분야에서 중요한 역할을 합니다. CNN은 이미지의 공간적 계층구조를 학습하여 객체의 위치 변화에 강건한 특징을 추출할 수 있습니다.
LeNet(1998)

1998년에 Yann LeCun과 그의 동료들이 개발한 컨볼루션 신경망 구조입니다. 이는 손으로 쓴 우편번호를 인식하는 데 사용되었습니다.
LeNet은 컨볼루션 계층과 평활화 계층(풀링)으로 구성되어 있으며, 이미지에서 특징을 추출하고 분류하는 데 효과적으로 사용되었습니다. 이는 딥러닝 분야에서 첫 번째로 성공적으로 적용된 컨볼루션 신경망 구조 중 하나입니다. LeNet은 신경망의 깊이와 너비를 조절하여 다양한 이미지 처리 작업에 적용할 수 있는 기본적인 아이디어를 제시했습니다.
AlexNet

2012년에 Alex Krizhevsky, Ilya Sutskever 및 Geoffrey Hinton에 의해 개발된 딥러닝 아키텍처입니다.
이는 ImageNet Large Scale Visual Recognition Challenge에서 매우 높은 정확도로 우승하여 딥러닝의 발전을 이끌었습니다. AlexNet은 LeNet과 유사한 구조를 가지고 있지만 훨씬 더 깊고 넓은 신경망으로 구성되어 있습니다. 이 모델은 여러 개의 컨볼루션 레이어와 풀링 레이어, 그리고 완전 연결된 레이어로 구성되어 있으며, ReLU(Rectified Linear Unit) 활성화 함수를 사용하여 비선형성을 도입했습니다. 또한 드롭아웃(dropout)과 데이터 증강(data augmentation)과 같은 기법을 사용하여 과적합을 방지하고 일반화 성능을 향상시켰습니다. AlexNet은 딥러닝 분야에서 컨볼루션 신경망의 급격한 발전을 이끈 중요한 모델 중 하나로 인정받고 있습니다.
VGGNet

2014년에 개발된 컨볼루션 신경망 아키텍처로, Visual Geometry Group(VGG)에서 개발되었습니다.
VGGNet은 딥러닝 분야에서 기존의 다른 모델들과 달리 매우 깊은 네트워크 구조를 가졌으며, 이는 여러 개의 컨볼루션 레이어와 풀링 레이어로 구성된 깊은 신경망을 통해 특징을 추출하는 방식을 채택했습니다.
VGGNet은 3x3 크기의 작은 커널을 사용하는 여러 개의 컨볼루션 레이어로 구성되어 있으며, 이는 네트워크를 더 깊게 만들고 매개 변수 수를 줄여 성능을 향상시킵니다. 또한 VGGNet은 완전 연결 레이어로 구성된 깊은 신경망을 사용하여 이미지 분류 및 다른 비전 작업에서 우수한 성능을 보여주었습니다.
VGGNet은 단순하고 효율적인 아키텍처로 구현되어 있어 이해하기 쉽고 구현하기도 쉬우며, 다양한 컴퓨터 비전 작업에서 널리 사용되고 있습니다.
GoogleNet(2014)

2014년에 발표된 딥러닝 모델로, 인셉션(Inception) 아키텍처를 기반으로 합니다. 이 모델은 Google의 연구팀에 의해 개발되었으며, 딥러닝 모델의 성능과 효율성을 개선하기 위해 설계되었습니다.
GoogleNet은 이전의 다른 딥러닝 모델과 비교하여 효율적인 네트워크 구조를 가지고 있습니다. 이 모델은 인셉션 모듈이라고 불리는 다양한 크기의 컨볼루션 필터를 병렬로 적용하여 네트워크를 효율적으로 확장할 수 있는 구조를 도입했습니다. 이를 통해 모델의 깊이를 증가시키면서도 매개 변수 수를 줄이고 연산 효율성을 높였습니다.
또한 GoogleNet은 1x1 컨볼루션 레이어를 사용하여 차원 축소와 비선형성을 도입하여 네트워크의 효율성을 높였습니다. 이러한 설계는 모델의 성능을 향상시키면서도 계산 비용을 낮추고 메모리 사용량을 줄였습니다.
GoogleNet은 이미지 분류, 객체 탐지, 이미지 생성 및 기타 컴퓨터 비전 작업에서 널리 사용되며, 딥러닝 모델의 혁신적인 설계와 효율성으로 주목받고 있습니다.
ResNet(Residual Network)

2015년에 Microsoft Research에서 개발된 딥러닝 신경망 구조입니다. ResNet은 심층 신경망의 효율성을 향상시키기 위한 중요한 개념인 잔여 학습(residual learning)을 도입하여 기존의 다른 네트워크보다 훨씬 깊은 구조를 가질 수 있게 되었습니다.
ResNet의 핵심 아이디어는 스킵 연결(skip connection) 또는 잔여 연결(residual connection)을 사용하여 네트워크의 각 레이어가 이전 레이어의 출력에 직접 연결되도록 하는 것입니다. 이렇게 하면 레이어를 추가할 때마다 네트워크의 성능이 감소하는 문제를 해결할 수 있습니다. 스킵 연결은 그레디언트 소실 문제를 완화하고 학습을 더 깊게 할 수 있도록 도와줍니다.
ResNet은 일반적으로 각 블록에 대해 잔차 유닛(residual unit)을 사용하여 네트워크를 구성합니다. 잔차 유닛은 스킵 연결을 포함하고 있으며, 입력값과 출력값의 차원이 동일하도록 조정됩니다. 이를 통해 네트워크가 깊어질수록 효과적으로 학습될 수 있습니다.
ResNet은 ImageNet과 같은 대규모 데이터셋에서 이미지 분류, 객체 탐지 및 분할 등의 다양한 컴퓨터 비전 작업에서 우수한 성능을 보여주었습니다. 또한 ResNet의 아이디어는 다른 신경망 구조에도 널리 적용되어 현재의 딥러닝 모델 개발에 큰 영향을 미치고 있습니다.
DenseNet

DenseNet은 2016년에 개발된 딥러닝 신경망 구조입니다. DenseNet은 밀집 연결(dense connectivity)이라는 개념을 도입하여 네트워크의 각 레이어가 이전 모든 레이어와 직접 연결되도록 설계되었습니다.
DenseNet은 ResNet과 비슷한 잔차 학습(residual learning)의 아이디어를 기반으로 하지만, ResNet에서는 각 레이어가 이전 레이어의 출력에 스킵 연결을 추가하는 반면, DenseNet에서는 각 레이어가 이전 모든 레이어의 출력에 직접 연결됩니다. 이러한 밀집 연결은 그레디언트의 전파를 개선하고 네트워크의 깊이에 대한 제약을 완화하여 학습을 더욱 효율적으로 만듭니다.
DenseNet은 각 레이어가 이전 레이어의 출력을 입력으로 받기 때문에 특성 맵이 모든 레이어를 통과하면서 정보가 계속해서 축적됩니다. 이는 네트워크가 보다 효율적으로 정보를 공유하고 재사용할 수 있도록 도와줍니다.
DenseNet은 주로 이미지 분류, 객체 탐지, 분할 등의 컴퓨터 비전 작업에서 사용되며, 특히 데이터가 제한적인 경우에도 효과적으로 작동합니다. 또한 DenseNet은 네트워크의 경량화 및 압축에도 유용하게 사용될 수 있습니다.
Object Detection
Object(Classification) + Region(Regression)
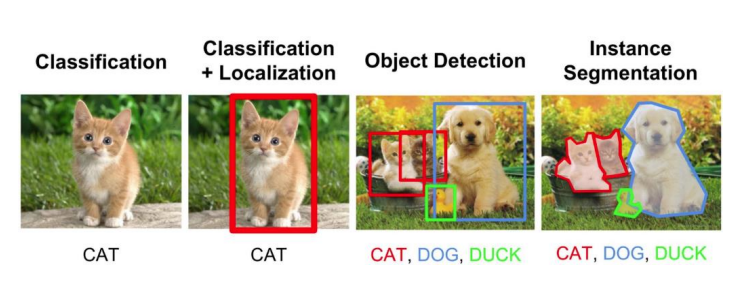
객체 탐지(Object Detection)는 컴퓨터 비전 분야에서 중요한 작업 중 하나로, 이미지나 비디오에서 여러 객체를 식별하고 그들의 위치를 지정하는 프로세스를 의미합니다. 객체 탐지는 일반적으로 두 가지 주요 작업을 포함합니다:
- 객체 분류(Classification): 이미지나 비디오 내에 존재하는 객체의 종류 또는 클래스를 식별하는 작업입니다. 이는 이미지 내에 여러 객체가 존재할 수 있으며, 각 객체가 어떤 클래스에 속하는지를 결정합니다. 이 작업은 주로 이미지 분류와 유사하지만, 여러 객체를 동시에 처리해야 하는 점에서 다릅니다.
- 영역 회귀(Region Regression): 이미지나 비디오에서 객체의 위치를 지정하고 경계 상자(bounding box)로 표시하는 작업입니다. 객체가 존재하는 위치를 정확하게 표시하기 위해 경계 상자를 특정 클래스의 객체 주위로 조정하거나 변경할 수 있습니다.
따라서 객체 탐지는 객체의 존재 여부를 확인하는 것뿐만 아니라, 각 객체의 클래스를 식별하고 위치를 정확하게 지정하는 것을 목표로 합니다. 이를 통해 컴퓨터 비전 시스템은 이미지나 비디오 속에서 객체를 식별하고 분류하여 다양한 응용 프로그램에 활용할 수 있습니다.

SPPNet은 Spatial Pyramid Pooling Network의 약자로, 이미지의 임의 크기에서 고정 크기의 특징 벡터로 풀링(pooling)하는 방법을 제안한 신경망 구조입니다. 이 방법은 객체 탐지(Object Detection)나 이미지 분류(Image Classification)와 같은 작업에서 사용됩니다.
주요 특징은 다음과 같습니다:
- 공간 피라미드 풀링(Spatial Pyramid Pooling): 이미지의 다양한 위치에서 특징을 추출하여 여러 크기의 특징 맵을 생성합니다. 이는 이미지의 크기에 관계없이 일정 크기의 특징 벡터를 얻을 수 있도록 합니다.
- 빈(bin)의 크기 및 수: 이미지의 크기에 비례하여 빈(bin)의 크기가 조절되며, 이미지 크기와 관계없이 고정된 수의 빈을 사용합니다. 이를 통해 다양한 크기의 이미지에서도 일관된 특징 벡터를 얻을 수 있습니다.
SPPNet은 이미지 내의 객체를 검출하고 분류하는 작업에서 이미지의 크기나 객체의 위치에 대한 제약을 줄여주는 데 사용됩니다. 따라서 더 유연한 객체 탐지 및 분류를 가능케 합니다.
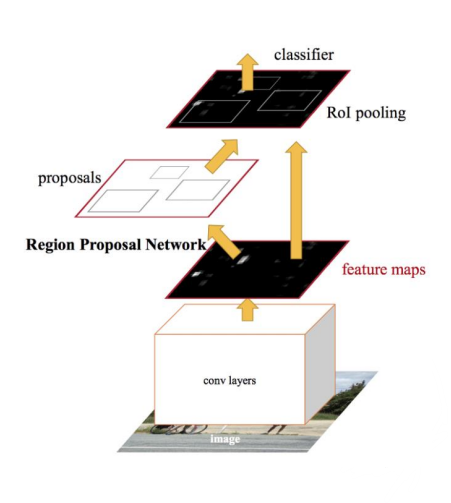
Fast R-CNN은 R-CNN의 단점을 극복하기 위해 개발된 객체 탐지 알고리즘입니다. R-CNN의 주요 단점은 지역 제안(Region Proposal) 단계에서 발생하는 지역화 조정(localization tuning)과 복잡성, 그리고 느린 속도였습니다. 이에 Fast R-CNN은 다음과 같은 특징을 가집니다:
- 전체 이미지에 대한 특징 맵 생성: 전체 이미지에 대해 한 번의 특징 맵을 생성합니다.
- 지역 제안의 특징 맵으로 투영: 지역 제안을 생성한 후, 이를 생성된 특징 맵에 투영합니다.
- RoI(Region of Interest) Pooling 레이어: SPP 레이어와 유사한 방식으로 RoI Pooling 레이어를 도입하여 고정 크기의 특징 벡터를 얻습니다.
- End-to-end 분류 및 회귀: 특징 추출, 지역 제안 생성, RoI 풀링, 분류 및 회귀를 하나의 end-to-end 구조로 통합합니다.
또한 Faster R-CNN은 Fast R-CNN의 한계인 지역 제안 단계의 병목을 극복하기 위해 개발되었습니다. 이는 다음과 같은 특징을 가집니다:
- 지역 제안 네트워크(RPN): 특징 맵 위에 슬라이딩하는 미니 fully-connected 네트워크를 사용하여 지역 제안을 생성합니다. 각 슬라이딩 윈도우에서 anchor box를 사용하여 k개의 지역 제안을 생성하고, 이들 각각에 대해 객체 또는 배경일 확률을 예측합니다.
- 불변성을 가진 앵커(Anchors): 다양한 크기와 종횡비를 가진 앵커를 사용하여 다양한 크기의 객체에 대한 지역 제안을 생성합니다.
- RPN 훈련: RPN을 훈련시키기 위해 IoU(Intersection over Union)와 다양한 클래스에 대한 멀티 태스크 손실 함수를 사용하여 지역 제안을 정확하게 조정합니다.
이러한 기술들은 객체 탐지 알고리즘의 성능을 향상시키고 속도를 높이며, 더욱 정확한 객체 위치를 얻을 수 있도록 합니다.
SSD
SSD(단일 샷 다중 상자 검출기, Single Shot MultiBox Detector)는 객체 탐지를 위한 신경망 기반 알고리즘입니다. SSD는 다음과 같은 특징을 가집니다:
- 출력 공간: 각 특징 맵 위치마다 다양한 종횡비와 스케일을 가진 기본 상자(default box)를 생성합니다.
- 선택적 검색을 기반으로 한 지역 제안: 다양한 종류의 객체를 검출하기 위해 선택적 검색(selective search)과 같은 방식을 사용하는 것은 계산 비용이 많이 들어간다는 단점이 있습니다. SSD는 이를 극복하기 위해 기본 상자를 사용하여 객체를 직접 예측하므로서 빠르고 효율적인 객체 검출을 제공합니다.
- 기본 상자(Default boxes)를 타겟으로: 각 위치에 몇 개의 다양한 종류의 기본 상자(default box)를 정의하고, 이들 각각에 대해 클래스별로 형상 오프셋과 신뢰도를 예측합니다. 이를 통해 다양한 크기와 모양의 객체를 검출할 수 있습니다.
- 검출 예측: 다양한 크기의 커널을 사용하여 특징 맵에서 객체를 예측합니다. 예측된 객체에 대한 클래스별 신뢰도를 얻습니다.
이러한 기술들은 객체 탐지의 속도와 정확도를 높이는 데 기여하며, 다양한 크기와 모양의 객체를 효과적으로 검출할 수 있습니다.
YOLO
YOLO(You Only Look Once)는 객체 탐지를 위한 신경망 기반 알고리즘으로, 이미지를 한 번만 처리하여 객체를 탐지하는 특징을 갖고 있습니다. YOLO는 다음과 같은 특징을 가지고 있습니다:
- 단일 네트워크 구조: 입력 이미지를 그리드로 나누고 각 그리드 셀마다 객체를 예측하는 단일 신경망을 사용합니다. 이로써 이미지를 여러 번 처리할 필요가 없어져 빠른 속도를 제공합니다.
- 그리드 셀 당 여러 개의 바운딩 박스 예측: 각 그리드 셀에서 여러 개의 바운딩 박스를 예측하고, 그 바운딩 박스들에 대해 객체가 존재할 확률을 예측합니다.
- 바운딩 박스 예측: 각 바운딩 박스의 중심 좌표와 너비, 높이를 예측하고, 객체가 속한 클래스를 분류합니다.
- 신뢰도 예측: 각 바운딩 박스의 신뢰도를 예측하여 해당 바운딩 박스에 객체가 존재하는 정확도를 파악합니다.
YOLO는 단일 네트워크로 구성되어 있으며, 객체 탐지를 위한 속도와 정확도를 높이는 데 기여합니다. 또한 다양한 크기와 모양의 객체를 효과적으로 탐지할 수 있는 장점을 가지고 있습니다.
Mask R-CNN
Mask R-CNN은 객체 인스턴스 분할을 위한 신경망 기반 알고리즘으로, Faster R-CNN의 변형입니다. Mask R-CNN은 다음과 같은 특징을 가지고 있습니다:
- 분류, 위치 추정, 시맨틱 분할: Mask R-CNN은 객체의 클래스를 분류하고, 바운딩 박스를 추정하여 객체의 위치를 지정합니다. 또한 객체의 픽셀별 세분화를 수행하여 시맨틱 분할을 제공합니다.
- Faster R-CNN의 확장: Faster R-CNN 구조를 기반으로 하며, 각 객체 인스턴스에 대한 세분화를 추가하는 마스크 분기(mask branch)를 도입하여 개선되었습니다.
- RoIAlign: RoIAlign은 Faster R-CNN의 RoIPooling을 개선한 것으로, 픽셀 정확도를 향상시킵니다. 이를 통해 더 정확한 객체 세분화를 얻을 수 있습니다.
- 마스크 예측: Mask R-CNN은 객체 인스턴스의 바운딩 박스를 예측하는 동시에, 각 객체에 대한 픽셀별 마스크를 예측합니다. 이를 통해 객체의 픽셀 수준의 분할을 수행할 수 있습니다.
Mask R-CNN은 객체 분류, 위치 추정, 시맨틱 분할을 효과적으로 수행하여 이미지에서 객체를 정확하게 식별하고 분할하는 데 사용됩니다. 이를 통해 다양한 응용 프로그램에서 객체 인식과 분할 작업을 수행할 수 있습니다.