[3장-4] 피마 인디언 당뇨병 예측
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix,classification_report,accuracy_score,precision_score,recall_score,f1_score# 파일 불러오기(구글 드라이브 연동)
from google.colab import drive
drive.mount("/content/drive")df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/diabetes.csv')
df.head()
- Pregnancies: 임신 횟수
- Glucose: 포도당 부하 검사 수치
- BloodPressure: 혈압(mm Hg)
- SkinThickness: 팔 삼두근 뒤쪽의 피하지방 측정값(mm)
- Insulin: 혈청 인슐린(mu U/ml)
- BMI: 체질량지수(체중(kg)/(키(m))^2)
- DiabetesPedigreeFunction: 당뇨 내력 가중치 값
- Age: 나이
- Outcome: 클래스 결정 값(0또는 1)
# 데이터 확인
df.info()
df.describe()
# 상관계수 반환
df.corr()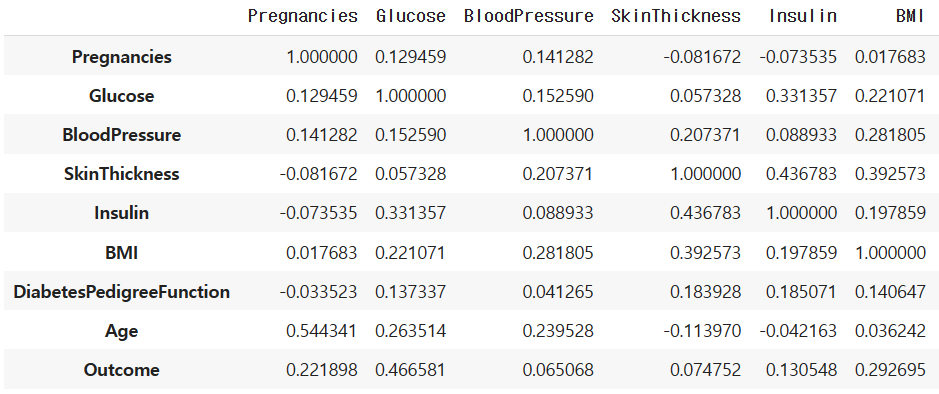
sns.heatmap(df.corr(), annot=True, fmt='.2f') #소수 둘째짜리: 0.2f 또는 .2f 사용 #annot=셀사용
# null값 확인
df.isnull().sum()
sns.boxplot(data=df, y=df['SkinThickness'])
sns.boxplot(data=df, y=df['Insulin'])
# 0값 피처 확인
num = df[df['SkinThickness']==0]
num1 = df[df['BloodPressure']==0]
num2 = df[df['Glucose']==0]
num3 = df[df['Insulin']==0]
num4 = df[df['BMI']==0]
num.shape, num1.shape, num2.shape, num3.shape, num4.shape((227, 9), (35, 9), (5, 9), (374, 9), (11, 9))
df[['Glucose', 'BloodPressure', 'BMI','Insulin','SkinThickness']] = df[['Glucose', 'BloodPressure', 'BMI','Insulin','SkinThickness']].replace(0, np.nan)# 0값을 평균값으로 대체
df[['Glucose', 'BloodPressure', 'BMI','Insulin','SkinThickness']] = df[['Glucose', 'BloodPressure', 'BMI','Insulin','SkinThickness']].fillna(df[['Glucose', 'BloodPressure', 'BMI','Insulin','SkinThickness']].mean())num = df[df['SkinThickness']==0]
num1 = df[df['BloodPressure']==0]
num2 = df[df['Glucose']==0]
num3 = df[df['Insulin']==0]
num4 = df[df['BMI']==0]
num.shape, num1.shape, num2.shape, num3.shape, num4.shape((0, 9), (0, 9), (0, 9), (0, 9), (0, 9))
# 시각화
X = df.drop(columns=['Outcome'])
y = df['Outcome']sns.countplot(data=df, x=y)
불균형 데이터 다루기: Resampling
* 각 클래스가 가지고 있는 데이터양 차이가 커서 불균형한 데이터셋
* 예시: 항공사고, 금융사기, 암진단, 광고클릭

- under-sampling
다수 클래스에서 샘플을 삭제하는 것.
간단한 구현은 무작위 records를 삭제하는 것이다.
다수의 정보를 잃는다.
- over-sampling
소수클래스에 샘플을 추가하는 것
간단한 구현은 다수클래스에서 무작위 records를 복제하는 것이다.
Overfitting 문제가 있다.
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=41)
X_ros,y_ros = ros.fit_resample(X,y)sns.countplot(data=df, x=y_ros)
데이터 전처리
1. #StandardScaler 2. #MinMaxScaler 3. #RobustScaler 4. #Normalizer
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)순차모델 : Sequential()
Sequential()을 사용하면 간단한 순차적인 구조를 가진 모델을 쉽게 구성할 수 있습니다. 즉, 입력층부터 출력층까지 차례대로 쌓아가는 것으로 모델을 구성합니다.
▶ Relu 함수
- ReLU(Rectified Linear Unit, 경사함수)는 가장 많이 사용되는 활성화 함수 중 하나로, Sigmoid와 tanh가 갖는 Gradient Vanishing 문제를 해결하기 위한 함수이다.

- x가 0보다 크면 기울기가 1인 직선, 0보다 작으면 함수 값이 0이 된다. 이는 0보다 작은 값들에서 뉴런이 죽을 수 있는 단점을 야기한다.
또한 sigmoid, tanh 함수보다 학습이 빠르고, 연산 비용이 적고, 구현이 매우 간단하다는 특징이 있다.
참고
딥러닝 - 활성화 함수(Activation) 종류 및 비교 : 네이버 블로그 (naver.com)
딥러닝 - 활성화 함수(Activation) 종류 및 비교
# 활성화 함수 딥러닝 네트워크에서 노드에 입력된 값들을 비선형 함수에 통과시킨 후 다음 레이어로 전달...
blog.naver.com
from keras.models import Sequential
from keras.layers import Dense
model = Sequential([
Dense(150,activation='relu',name='a1',input_shape=(X_train.shape[1],)),
Dense(100,activation='relu',name='a2'),
Dense(50,activation='relu',name='a3'),
Dense(25,activation='relu',name='a4'),
Dense(1,activation='sigmoid',name='a5')import tensorflow as tf
model.compile(
loss = tf.keras.losses.BinaryCrossentropy(),
optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=0.001),
metrics=['accuracy'])model.fit(X_train, y_train, epochs=55,batch_size=32)
y_pred = model.predict(X_test)
for i in range(len(y_pred)):
if y_pred[i]>0.5:
y_pred[i]=1
else:
y_pred[i]=0print("Accuracy:", accuracy_score(y_test, y_pred))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("Classification Report:")
print(classification_report(y_test, y_pred))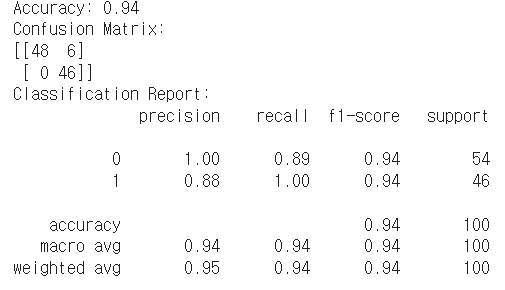
▶ 코드 정리: 캐글스터디_파마 인디언 당뇨병 예측 - Colaboratory (google.com)
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com