[헷갈리는 개념] SQLD 대비 정리1
1. 분산 데이터베이스 특징
-처리 비용의 증가 → 다수의 지역에 원격지원 비용 → 소프트 개발 비용 증가
-지역 자치성, 점증적 시스템 용량 확장
-오류 잠재성 증대
-빠른 응답 속도와 통신 비용 증대
-데이터 무결성 위험 있음(멀리 떨어져 있어서)
2. 데이터 및 프로세스 관점
- 데이터 관점: 업무가 어떤 데이터와 관련 있는지, 데이터 간의 관계는 무엇인지 모델링하는 관점
- 프로세스 관점: 업무가 실제로 하고 있는 일은 무엇인지, 무엇을 해야되는지 모델링하는 관점
- 데이터와 프로세스의 상관관점: 업무가 처리하는 일의 방법에 따라 데이터가 어떻게 영향을 받고 있는지 모델링하는 관점
3. Hash join 기법: 작은 테이블을 먼저 읽고 조인
-조인 작업을 수행할 때는 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는것이 좋다
→ 응답속도 빨라짐
-두개의 테이블 간에 조인을 할 때 범위 검색이 아닌 동등 조인에 적합한 방식/ 동등조건에만 사용(=)
-해시 테이블을 저장할 때 메모리에 적재할 수 있는 영역의 크기보다 커지면 초과한 크기는 임시영역 디스크로 저장한다 → 하드디스크에 저장해 속도 느림
-작은 테이블을 먼저 읽어서 hash area에 해시 테이블을 생성하는 방법으로 큰 테이블로 hash area를 생성하면 과다한 sort가 유발되어 성능 저하될 수 있다
-해시조인은 수행 빈도가 낮고 수행시간이 오래 걸리는 대용량 테이블에 대한 조인을 할때 유용한다
* 온라인 트랜잭션 OLTP : 해시조인보다 중첩 방식 유용. 그 이유는 NESTED LOOP 방식은 적은 데이터를 조인할 때 유리한 구조이기 때문
4. 반정규화 기법
테이블의 반정규화 기법 중 데이터 무결성을 깨뜨릴 위험을 갖지 않고서도 데이터 처리의 성능을 향상시킬 수 있는 기법
→ 중복관계추가
5. ERD: Entity Relationship Diagram
- 1과 2의 자료를 하나로 만들 때 → 2개의 서브타입으로 나눠서 저장
5. 정규화
-제1정규화: 원자성을 가지게 만들어줌 → 모든 속성 중복x / 모든 속성은 반드시 하나의 값을 가져야한다
-제2정규화: 식별자의 부분속성에 대해서만 종속관계인 부분함수를 제거 → 기본키가 2개 이상 컬럼으로 되어 있는 형태
-제3정규화: 식별자를 제외한 일반 속성들에 대한 이행함수 종속성 제거 / 속성 간 종속성을 가지면 안된다
-BCNF: 다수의 주식별자를 분리시킨다
6. 컬럼명
- 수정: MODIFY, RENAME
- 제약조건 추가: ADD
7. 동일한 결과값을 반환하는 함수
GROUP BY CUBE(DEPTNO, JOB): 과 동일한 결과값을 반환하는 함수
→ GROUP BY GROUPING SETS(DEPTNO, JOB, (DEPTNO, JOB), ()):
8. 정리
1) ROLLUP: ROLLUP함수는 소그룹간의 합계를 계산하는 함수입니다. ROLLUP을 사용하면 GROUP BY로 묶은 각각의 소그룹 합계와 전체 합계를 모두 구할 수 있습니다.
👉🏼 맨 아래 행에 전체 합계!!
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY ROLLUP(상품ID, 월);

NULL값으로 표시된 부분들이 바로 ROLLUP함수를 써서 나온 합계입니다.
P001 그룹의 매출액 합계, P002 그룹의 매출액 합계, P003 그룹의 매출액 합계가 각각 계산되었으며 전체 Total 합계 또한 한 번에 표시할 수 있습니다.
결과값에서 알 수 있듯이 GROUP BY절에 명시한 모든 컬럼에 대한 소그룹의 합계를 구해주는 것이 아니고 맨 처음 명시한 컬럼에 대해서만 소그룹 합계를 구해줍니다.
GROUP BY ROLLUP(컬럼1, 컬럼2)
=
GROUP BY 컬럼1, 컬럼2
UNION ALL
GROUP BY 컬럼1
UNION ALL 모든 집합 그룹 결과
2) CUBE: CUBE함수는 항목들 간의 다차원적인 소계를 계산합니다. ROLLUP과 달리 GROUP BY절에 명시한 모든 컬럼에 대해 소그룹 합계를 계산해줍니다.
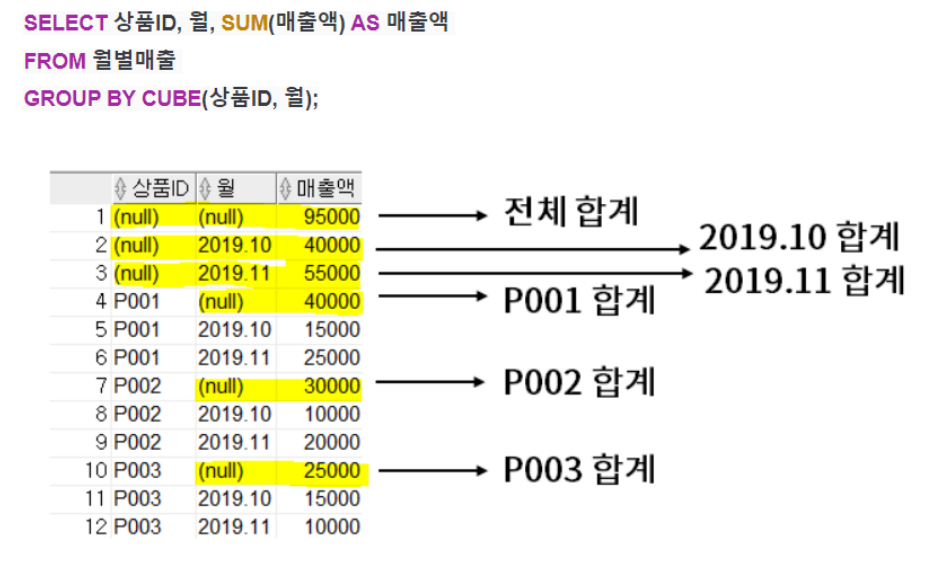
ROLLUP함수를 사용했을 때보다 결과가 좀 더 복잡합니다. 상품ID별 합계뿐만 아니라 월별 합계까지 한 번에 볼 수 있습니다.
3) GROUPING SETS: 특정 항목에 대한 소계를 계산하는 함수입니다.
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY GROUPING SETS(상품ID, 월);

ROLLUP과 CUBE는 GROUP BY 결과에 소그룹 합계와 토탈 합계를 보여주지만
👉🏼 GROUPING SETS는 각 소그룹별 합계만 간단하게 보여줍니다.
4) GROUPING: 직접적으로 그룹별 집계를 구하는 함수는 아니지만 위의 집계함수들을 지원하는 함수입니다.
- 집계가 계산된 결과에 대해서는 1의 값을 갖고 그렇지 않은 결과에 대해서는 0의 값을 갖습니다.
SELECT
CASE GROUPING(상품ID) WHEN 1 THEN '모든 상품ID' ELSE 상품ID END AS 상품ID,
CASE GROUPING(월) WHEN 1 THEN '모든 월' ELSE 월 END AS 월,
SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY ROLLUP(상품ID, 월);

CASE WHEN문을 사용해서 맨 처음에 단순 ROLLUP함수만 썼을 때 NULL값으로 표시되었던 곳에 값을 넣어주었습니다. 집계가 계산된 결과에 대해서만 값을 넣어주면 되기 때문에 GROUPING(컬럼명)=1인 경우에만 '모든상품ID' 또는 '모든월' 값을 부여했고 0인 경우에는 원래대로 상품ID와 월을 써주었습니다.
9. 비교

10. 계층형 쿼리
-START WITH: 루트노드 시작위치 지정
-CONNECT BY: 부모 계층형 쿼리에서 부모 노드와 자식 노드와의 관계를 설명
-PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 순방향 전개 수행한다
11. 계층형 쿼리의 내장함수
-LEVEL
-SYS_CONNECT_BY_PATH / 경로표시
-CONNECT_BY_ROOT / 전개할 데이터의 루트노드 표시
12. CASCADE CONSTRAINT
-제약조건으로 연결 되어 있는 부분에서 부,모 테이블의 기본키를 한번에 지울 수 없음(자식 테이블에서는 지울 수 있음)
-해당 테이블과 관계가 있고 참조되는 제약 조건에 대해서도 삭제를 수행한다
-oracle에서만 사용
13. 파티션 설명
1) RANK() OVER(PARTITION BY JOB ORDER BY 급여 DESC) JOB RANK:
→ 각 JOB별 급여가 높은 순서대로 순위 부여
14. 중복제거 함수
UNION → 중복제거
15. PRIMARY KEY
-후보키 중에서 선택된 식별자로서 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성이며 기본적으로 null 값을 가질 수 없다
- 속성에는 동일한 값이 중복되어 저장될 수 없다
16. 요약
- ROLLUP 소그룹, 전체합계 / 맨 아래 전체행 합계 있음
- CUBE GROUP BY에 명시한 모든 컬럼에 대한 소그룹 합계
- GROUPING SETS 특정 항목에 대한 소계 계산 간단히
참고자료
https://for-my-wealthy-life.tistory.com/44