1. 싸이킷런(scikit-learn)
- 머신러닝을 위한 다양한 알고리즘과 개발을 위한 편리한 프레임워크, API 제공
- numpy와 scipy 기반에서 구축된 라이브러리
2. 용어 정리
- 피처(feature) : 일반 속성
- 레이블 : 타겟 값이 분류일 경우 → 데이터 학습을 위해 주어지는 정답 데이터
- 클래스 : 타겟 값이 분류일 경우 → 데이터 학습을 위해 주어지는 정답 데이터
- 타켓(값) → 학습할 값
- 결정(값)
3. 분류 예측 프로세스
1) 데이터 세트 분리(학습 데이터 / 테스트 데이터)
2) 모델학습
3) 예측수행
4) 평가(결과 비교 및 정확도 평가)
4. 사이킷런 기반 프레임워크
학습 : fit()
예측 : predict()
1) 내장 예제 데이터셋
- datasets.load_boston() : 보스턴 집값 가격 예측
- datasets.load_breast_cancer() : 위스콘신 유방암 피처들과 악성/음성 레이블 데이터 세트
- datasets.load_diabetes() : 당뇨 데이터 세트
- datasets.load_digits() : 0~9까지 숫자의 이미지 픽셀 데이터 세트
- datasets.load_iris() : 붓꽃 피처 데이터 세트
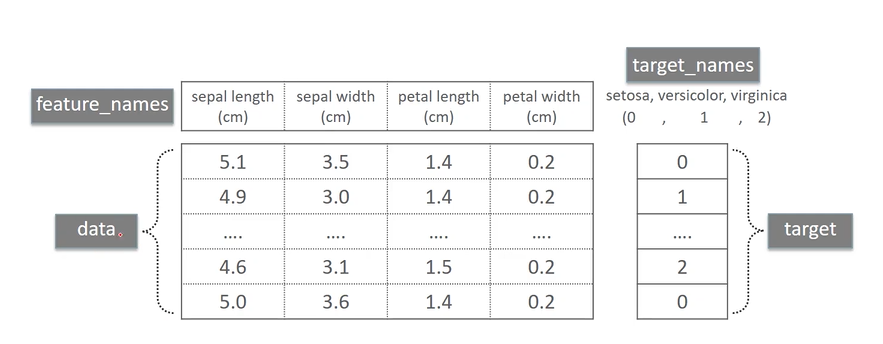
from sklearn.datasets import load_iris
iris_data = load_iris()
print(type(iris_data))keys = iris_data.keys()
print('붓꽃 데이터 세트의 키들:', keys)붓꽃 데이터 세트의 키들: dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
5. 학습데이터와 테스트 데이터
# 학습 데이터와 테스트 데이터 세트로 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)
# X : 피쳐, y: 타겟으로 관습적으로 사용
# feature: iris_data
# target data : iris_label
# test_size : 20%만 테스트 데이터로 만들어라
# random_stata : 호출할 때마다 동일한 학습/테스트용 데이터 세트를 생성하기 위해 주어진 값
6. 교차검증
- 실제 모델에 적용 전 검증하는 용도(검증 데이터 세트)
1) k폴드 교차 검증
- k=5 → 5번 학습 및 검증 평가 반복 수행
- 4/5: 학습, 1/5 검증 → 검증 위치를 계속 바꿈 (검증 평가1, 검증 평가2, 검증 평가3, 검증 평가4, 검증 평가5)
→ 평균값 산출
* 파이썬 머신러닝 완벽가이드_인프런 강의
'Machine Learning > 캐글스터디(파이썬 머신러닝)' 카테고리의 다른 글
| [3장-3] 피마 인디언 당뇨병 예측 (0) | 2023.04.08 |
|---|---|
| [3장-2] 정밀도와 재현율의 맹점 (0) | 2023.04.07 |
| [3장-1] 분류 성능 평가 지표 (0) | 2023.04.04 |
| [2장-3] 타이타닉 생존자 예측 ML 구현 (0) | 2023.04.03 |
| [2장-2] 붓꽃 품종 예측_파이썬 머신러닝 완벽가이드 (0) | 2023.03.20 |