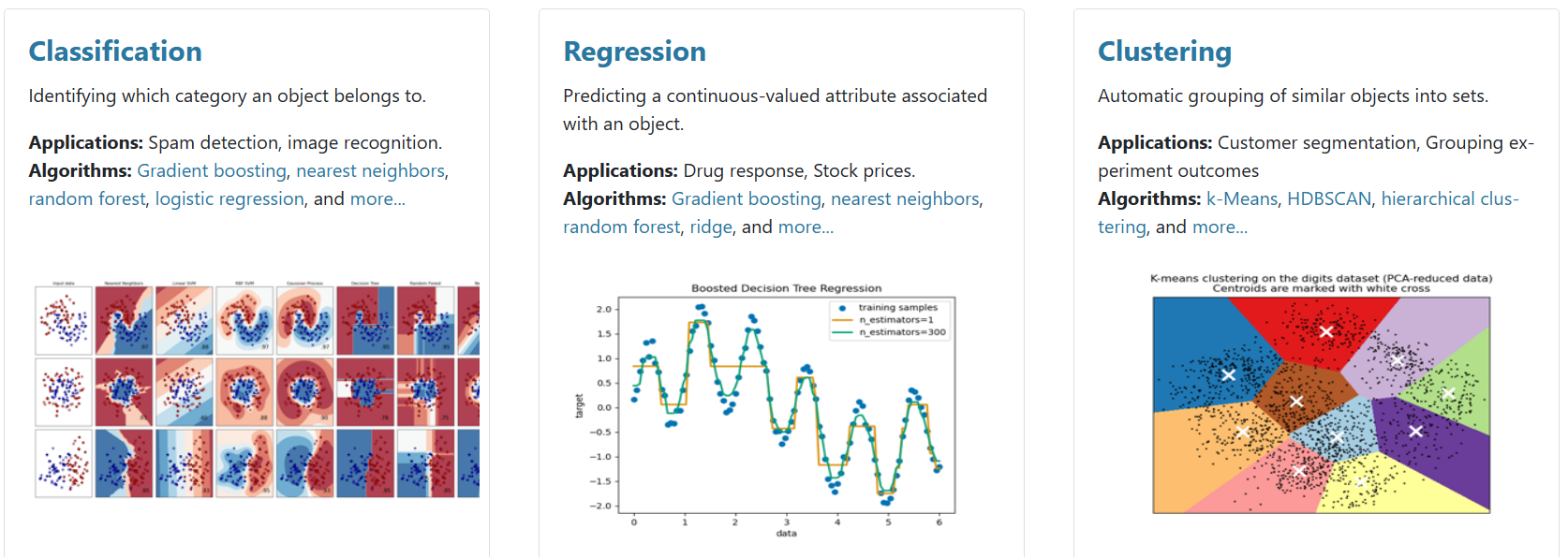
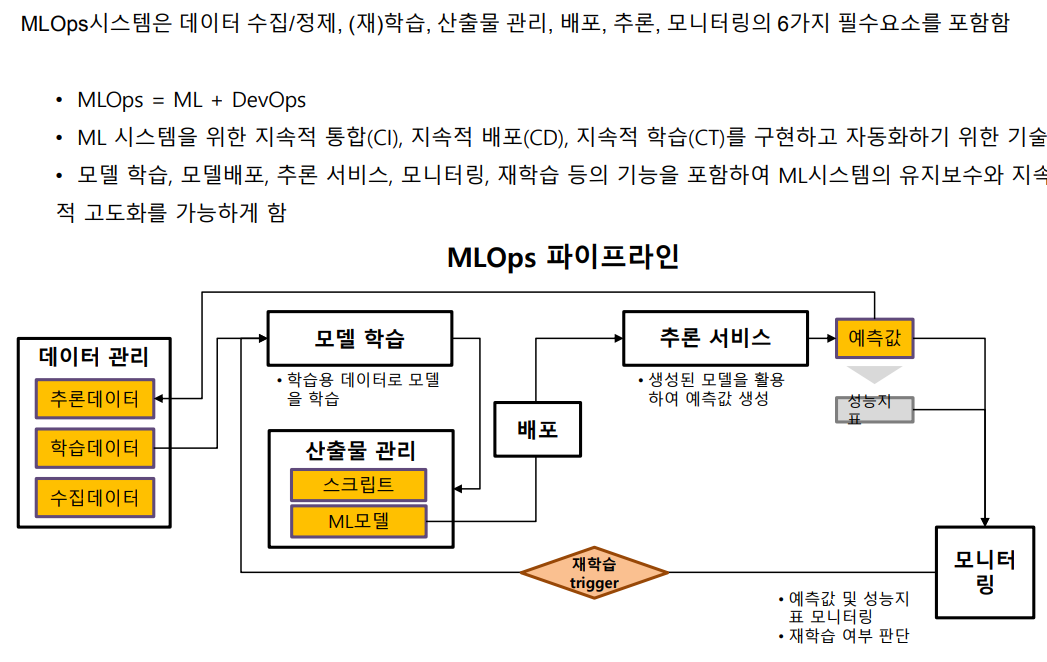
사이킷런이란? 사이킷런은 대표적인 파이썬 머신러닝 라이브러리로 Classification(분류), Regression(회귀) 모델을 주로 사용합니다. scikit-learn: machine learning in Python — scikit-learn 1.3.2 documentation scikit-learn: machine learning in Python — scikit-learn 1.3.2 documentation Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross vali..