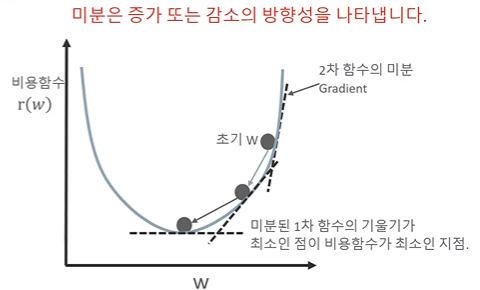
1. 텍스트 전처리 1) 토큰화: 주어진 텍스트를 작은 부분인’ 토큰’으로 나누는 과정/ 문장을 개별 단어로 분리하는 것을 의미함. ➔ 예시: 구두점 제외시키기: 마침표. 컴마, 물음표? 세미콜론; 느낌표! - I love music -> [“i”, “love”, “music”] 으로 변환 ➔ 토큰화 고려점: * 구두점이나 특수문자를 단순히 제외해서는 안된다.($45.55 123,456,789 ->문장의 경계를 알 수 있는데 도움이 됨) * 줄임말과 단어 내에 띄어쓰기가 있는 경우 (we're -> we are, i'm -> i am) ➔ 한국어 토큰화 문제점: 교착어의 문제, 한국어는 영어보다 띄어쓰기가 잘 지켜지지 않는다. 2) 정규화: 다양한 형태의 텍스트를 일관된 형태로 변환하는 작업(동일한 의미..