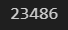1. Data Women's E-Commerce Clothing Reviews (kaggle.com) Women's E-Commerce Clothing Reviews 23,000 Customer Reviews and Ratings www.kaggle.com 2. Code ## Calling libraries !pip install textblob !pip install cufflinks import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from textblob import TextBlob from nltk import word_tokenize,pos_tag from plotly.offlin..