표본추출과 표본분포 (week 6)
데이터분석을 위한 통계
랜덤 표본 (random sample) 추출
:알려진 확률 분포로부터 임의로 데이터를 생성
예를 들어, 지난 몇년간 통계학 입문 강좌를 수강하는 학생들의 기말시험성적이 평균 50점, 표준편차 20점의 정규분포를 따른다는 사실을 알고 있다고 하자. 이 분포를 따르는 성적자료 100개를 임의로 생성해보자.
n=100, mean=50, sd=20, rnorm() : 정규분포
rnorm(n, mean=0, sd=1)
sample.data<-rnorm(n=100, mean=50, sd=20)
sample.data평균 추출
mean(sample.data)표준편차 추출
sd(sample.data)히스토그램 그리기
hist(sample.data)
이항분포에서 랜덤표본 추출
시행 횟수가 size이고, 성공률이 p인 베르누이 시행을 했을 때의 성공 횟수를 n번 추출하려면:
x<- rbinom (n=100, size=1, p=0.8)
x
카이제곱 분포
- 확률 밀도함수
x<-seq(0,10,by=0.01)
for ( i in c(1,2,3,4,6,10)){
chi.x<-dchisq(x,df=i)
if (i==1){plot(chi.x~x,type="l",ylim=c(0,0.5),
col=i,ylab="density")}
else{lines(chi.x~x,type="l",col=i)}
}
legend("topright",legend=c("1","2","3","4","6","10"),
col=c(1,2,3,4,6,10),lty=c(1,1,1,1,1,1))
- 랜덤표본 추출
y<-rchisq(n=100, df=5)
hist(y)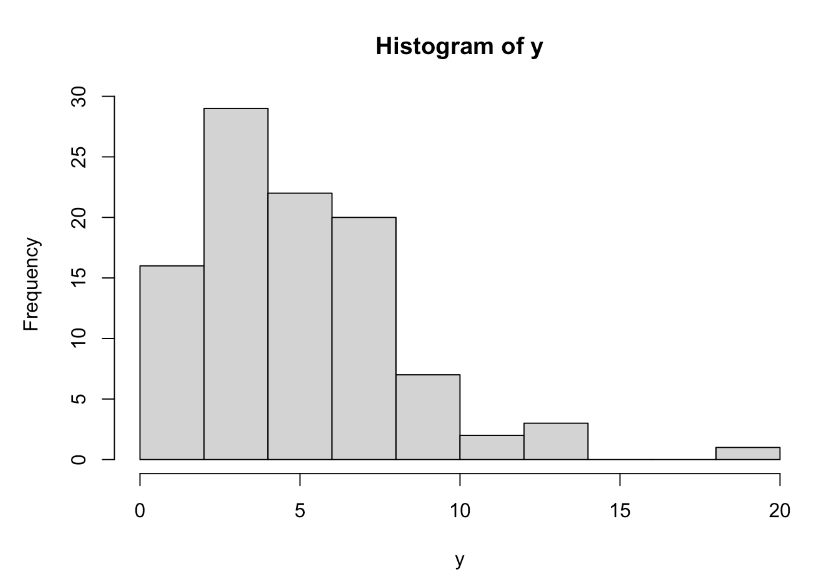
mean(y)var(y)t분포의 pdf 그리기
x<-seq(-5,5,by=0.01)
for ( i in c(2,3,5,10)){
t.x<-dt(x=x, df=i)
if (i==2){ plot(t.x~x,type="l",ylim=c(0,0.5),
col=i,ylab="density")}
else{lines(t.x~x,type="l",col=i)}
}
legend("topright",legend=c("2","3","5","10"),
col=c(2,3,5,10), lty=c(1,1,1,1))

x<-seq(-10,10,by=0.01)
Z<-rnorm(10000)
n<-10
V<-rchisq(10000,df=n)
tval<-Z/sqrt(V/n)
hist(tval, freq=FALSE, ylim=c(0,0.5))
t.d<-dt(x,df=n)
lines(t.d~x,type="l")

mean(tval); var(tval); n/(n-2)모평균에 대한 신뢰구간
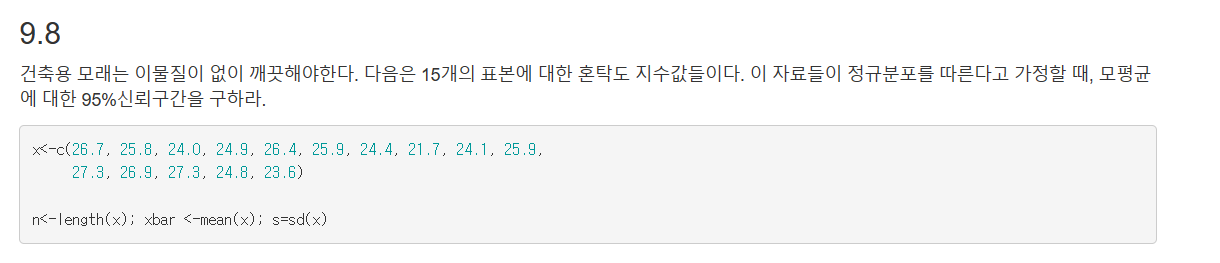
사과의 평균 무게(mu)에 대한 95% 신뢰구간은? 주어진 자료는 아래와 같음. n=30, xbar = 340, s=50, alpha = 0.05
# 𝑛이 충분히 크면 표본의 표준편차 s가 모집단의 표준편차 sigma에 가까울 것이므로 sigma를 s로 대체하여 구함
n <- 30
xbar <- 340
s <- 50
z.cut <- abs(qnorm(0.025))
lb <- xbar - z.cut*(s/sqrt(n))
ub <- xbar + z.cut*(s/sqrt(n))
print(c(xbar, lb,ub))# 모분산을 모를때, t 분포 사용
t.cut <- qt(0.025, df=n-1, lower.tail = F)
lb <- xbar - t.cut*(s/sqrt(n))
ub <- xbar + t.cut*(s/sqrt(n))
print(c(xbar, lb,ub))모비율 신뢰구간 구하기
### 총 100명의 학생 중 흡연자는 29명(smoke=1), 비흡연자는 71명(smoke=0)이었다.
### 흡연을 하는 학생의 비율의 95% 신뢰구간은?
x<-29; n<-100
phat<-x/n
se<-sqrt(phat*(1-phat)/n)
c(phat - 1.96*se, phat + 1.96*se) ## Confidence interval (Wald)prop.test(x=29, n=100, correct=FALSE) # Score-test base CI모평균 검정
예) 콜레스테롤 수치를 낮추는데 있어서 운동을 하는 것이 효과적인가를 판단하는 방법은?
## H0 : mu = 200 vs H1 : mu<200
## Data: xbar = 190, sd = 24, n=40
mu0 = 200
xbar = 190; sigma=24; n=40
## significance level
alpha<-0.05
## test statistics
Z<- (xbar - mu0)/(sigma/sqrt(n))
Z## [1] -2.635231## critical value approach
cut<-qnorm(alpha)
cut## [1] -1.644854Z < cut## [1] TRUE## p-value approach
pval <- pnorm(Z) # p-value
pval## [1] 0.004203997pval< alpha## [1] TRUEex1 자료가 모집단 (전국 학생들)의 임의 표본이라고 가정할 때, 중간고사 성적의 모평균이 75점이라고 할 수 있는가?
# one sample t-test (모분산을 모를때)
# H0: mu=75
# H1: not H0
ex1 <- read.csv("/Users/donghwan/Dropbox/Teaching/22-2/DS_stat/STAT_Basic/Note/Data/ex1.csv", header = T)
t.test(ex1$Midterm, mu = 75, alternative = "two.sided")##
## One Sample t-test
##
## data: ex1$Midterm
## t = -0.50261, df = 59, p-value = 0.6171
## alternative hypothesis: true mean is not equal to 75
## 95 percent confidence interval:
## 71.51314 77.08686
## sample estimates:
## mean of x
## 74.3## p-value: 0.6171 > 0.05유의수준 0.05 < p-value 값 0.6171 이므로, 이 모평균이 75점이라는 가설을 기각하지 못한다.
모비율 검정
예) 총 100명의 학생 중 흡연자는 29명(smoke=1), 비흡연자는 71명(smoke=0)이었다. 흡연을 하는 학생의 비율이 0.2보다 큰지 검정해보시오.
#One sample proportion test
#Normal approximation (정규근사)
#H0: p = 0.2
#H1: p > 0.2
prop.test(x=29, n=100, p=0.2, alternative = "greater")# 정규분포로 근사하지 않고, 이항분포 사용
# Exact binomial test
binom.test(x=29, n=100, p=0.2, alternative = "greater")두 집단의 평균 비교
### ex1 자료가 모집단 (전국 학생들)의 임의 표본이라고 가정할 때, 남학생과 여학생 집단의 기말고사 성적을 비교.
ex1 <- read.csv("/Users/donghwan/Dropbox/Teaching/22-2/DS_stat/STAT_Basic/Note/Data/ex1.csv", header = T)
Final_M <- ex1[ex1$Gender=="M",]$Final
Final_F <- ex1[ex1$Gender=="F",]$Final
boxplot(Final_M, Final_F)

1) 95% 신뢰구간 구하기
n=50, mean=162, sd=5
162 - 1.96 * (5 / sqrt(50)) <= m <= 162 + 1.96 * (5 / sqrt(50))
> 162 - 1.96 * (5 / sqrt(50))
[1] 160.6141
> 162 + 1.96 * (5 / sqrt(50))
[1] 163.3859
> n <- 50
> mu <- 162
> sigma <- sqrt(5^2 / n)
> interval <- mu + c(-1.96, 1.96) * sigma
>
> interval
[1] 160.6141 163.3859
2) 최소 몇명의 표본 필요
n = (z*(sigma/1))^2
n = (1.96 * 5 / 1)^2
n = 96.04
→ 최소 97명 필요

1) 점추정값 표준편차 계산
점 추정값: p̂ = X / n = 130 / 500 = 0.26 표준편차: s = sqrt(p̂(1-p̂) / n) = sqrt(0.26(1-0.26) / 500) = 0.031
2) 모시청률의 95% 신뢰구간 구하기
p̂ ± z* (sqrt(p̂(1-p̂) / n))
0.26 ± 1.96 * (0.031)
0.20 ~ 0.32
우리는 95% 신뢰도로 이 프로그램의 실제 인구 시청률이 20%에서 32% 사이에 있다고 말할 수 있다.

1)
p̂ ± z* (sqrt(p̂(1-p̂) / n))
p̂ = 25/100 = 0.25
z = 2.576
n = 100
0.25 ± 2.576 * (sqrt(0.25(1-0.25) / 100))
즉, 0.25 ± 0.137
99% 신뢰수준에서 면역성을 가진 성인의 모비율 p에 대한 신뢰구간은 0.113부터 0.387
2)
z = 2.576
E = 0.01
p̂ = 0.25
n = (2.576 / 0.01)^2 * 0.25(1-0.25)
n = 16,711.68
최소 16,712명 표본 조사 필요

* 양측검정
n=81
자유도 n-1=80
신뢰수준이 95%이므로, 양측 검정에서 각각 2.5%의 임계값을 갖는 t-분포를 사용
임계값은 qt(0.025, df=80) = -1.990, qt(0.975, df=80) = 1.990
신뢰구간 = 23 ± 1.990 * (32,000 / √81) = 23 ± 7,942
즉, 95% 신뢰수준에서 구매량의 모평균은 23만원을 중심으로 약 ±7,942원의 범위 내에서 존재

'Data Science Issue' 카테고리의 다른 글
| [이대 인재개발원 행사] 방구석 진로 콘서트_데이터 분석가(비전공자) (1) | 2023.05.27 |
|---|---|
| [초청세미나] Microsoft AI MVP 전미정님 특강 (0) | 2023.05.21 |
| 부도예측모형 2 (0) | 2023.04.17 |
| 부도예측모형 (0) | 2023.04.17 |
| [초청세미나] AI를 활용한 치료 예측 모델 개발 및 프로세스 개선 사례들 (0) | 2023.04.15 |