회귀
* 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계기법
* 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법
- 머신러닝 회귀 예측의 핵심: 주어진 피처와 결정 값 데이터 기반에서 학습을 통해 최적의 회귀계수를 찾아내는 것.
- 회귀: 선형회귀/ 비선형 회귀
RSS(비용함수) 기반의 회귀 오류 측정 → 오류 값의 제곱을 구해서 더하는 방식
- 경사하강법(Gradient Descent) : 비용최소화 하기
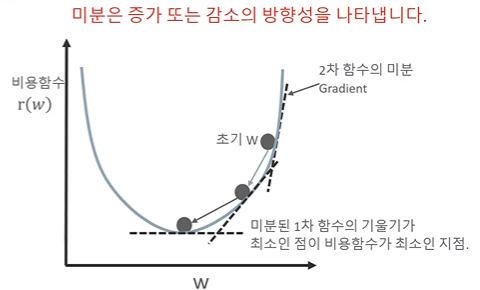
- 반복적으로 비용 함수의 반환 값, 즉 예측값과 실제 값의 차이가 작아지는 방향성을 가지고 W파라미터를 지속해서 보정해 나감. 오류값이 더 이상 작아지지 않으면 그 오류 값을 최소 비용으로 판단하고 그때의 W값을 최적 파라미터로 반환
파이썬 코드로 경사하강법 작성
실제값을 Y=4X+6 시뮬레이션하는 데이터 값 생성
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(0)
# y = 4X + 6 식을 근사(w1=4, w0=6). random 값은 Noise를 위해 만듬
X = 2 * np.random.rand(100,1)
y = 6 +4 * X+ np.random.randn(100,1)
# X, y 데이터 셋 scatter plot으로 시각화
plt.scatter(X, y)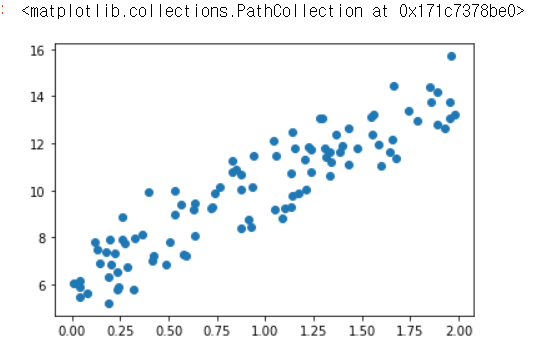
X.shape, y.shape((100, 1), (100, 1))경사하강법 수행 프로세스
w0과 w1의 값을 최소화 할 수 있도록 업데이트 수행하는 함수 생성
- 예측 배열 y_pred는 np.dot(X, w1.T) + w0 임 100개의 데이터 X(1,2,...,100)이 있다면 예측값은 w0 + X(1)w1 + X(2)w1 +..+ X(100)*w1이며, 이는 입력 배열 X와 w1 배열의 내적임.
# w1 과 w0 를 업데이트 할 w1_update, w0_update를 반환.
def get_weight_updates(w1, w0, X, y, learning_rate=0.01):
N = len(y)
# 먼저 w1_update, w0_update를 각각 w1, w0의 shape와 동일한 크기를 가진 0 값으로 초기화
w1_update = np.zeros_like(w1)
w0_update = np.zeros_like(w0)
# 예측 배열 계산하고 예측과 실제 값의 차이 계산
y_pred = np.dot(X, w1.T) + w0
diff = y-y_pred
# w0_update를 dot 행렬 연산으로 구하기 위해 모두 1값을 가진 행렬 생성
w0_factors = np.ones((N,1))
# w1과 w0을 업데이트할 w1_update와 w0_update 계산
w1_update = -(2/N)*learning_rate*(np.dot(X.T, diff))
w0_update = -(2/N)*learning_rate*(np.dot(w0_factors.T, diff))
return w1_update, w0_updatew0 = np.zeros((1,1))
w1 = np.zeros((1,1))
y_pred = np.dot(X, w1.T) + w0
diff = y-y_pred
print(diff.shape)
w0_factors = np.ones((100,1))
w1_update = -(2/100)*0.01*(np.dot(X.T, diff))
w0_update = -(2/100)*0.01*(np.dot(w0_factors.T, diff))
print(w1_update.shape, w0_update.shape)(100, 1)
(1, 1) (1, 1)반복적으로 경사 하강법을 이용하여 get_weigth_updates()를 호출하여 w1과 w0를 업데이트 하는 함수 생성
# 입력 인자 iters로 주어진 횟수만큼 반복적으로 w1과 w0를 업데이트 적용함.
def gradient_descent_steps(X, y, iters=10000):
# w0와 w1을 모두 0으로 초기화.
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
# 인자로 주어진 iters 만큼 반복적으로 get_weight_updates() 호출하여 w1, w0 업데이트 수행.
for ind in range(iters):
w1_update, w0_update = get_weight_updates(w1, w0, X, y, learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0예측 오차 비용을 계산을 수행하는 함수 생성 및 경사 하강법 수행
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y - y_pred))/N
return cost
w1, w0 = gradient_descent_steps(X, y, iters=1000)
print("w1:{0:.3f} w0:{1:.3f}".format(w1[0,0], w0[0,0]))
y_pred = w1[0,0] * X + w0
print('Gradient Descent Total Cost:{0:.4f}'.format(get_cost(y, y_pred)))w1:4.022 w0:6.162
Gradient Descent Total Cost:0.9935plt.scatter(X, y)
plt.plot(X,y_pred)
▶ 미니 배치 확률적 경사 하강법을 이용한 최적 비용함수 도출
→ 100개 중에 일부만 계산을 해도 잘 되기 때문에 아래를 많이 씀
def stochastic_gradient_descent_steps(X, y, batch_size=10, iters=1000):
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
prev_cost = 100000
iter_index =0
for ind in range(iters):
np.random.seed(ind)
# 전체 X, y 데이터에서 랜덤하게 batch_size만큼 데이터 추출하여 sample_X, sample_y로 저장
stochastic_random_index = np.random.permutation(X.shape[0])
sample_X = X[stochastic_random_index[0:batch_size]]
sample_y = y[stochastic_random_index[0:batch_size]]
# 랜덤하게 batch_size만큼 추출된 데이터 기반으로 w1_update, w0_update 계산 후 업데이트
w1_update, w0_update = get_weight_updates(w1, w0, sample_X, sample_y, learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0np.random.permutation(100)w1, w0 = stochastic_gradient_descent_steps(X, y, iters=1000)
print("w1:",round(w1[0,0],3),"w0:",round(w0[0,0],3))
y_pred = w1[0,0] * X + w0
print('Stochastic Gradient Descent Total Cost:{0:.4f}'.format(get_cost(y, y_pred)))w1: 4.028 w0: 6.156
Stochastic Gradient Descent Total Cost:0.9937사이킷런 Linear Regression 클래스
- 예측값과 실제 값의 RRS를 최소화하는 OLS 추정 방식으로 구현한 클래스
- fit() 메서드로 X,y 배열을 입력 받으면 회귀계수인 W를 coef_ 속성에 저장한다.
[선형 회귀의 다중 공선성 문제]
- 선형회귀는 입력 피처의 독립성에 많은 영향 받음
- 피처간의 상관관계가 매우 높은 경우 분산이 매우 커져서 오류에 매우 민감해짐(공선성 문제)
- 상관관계가 높은 피처가 많은 경우 독립적인 중요한 피처만 남기고 제거하거나 규제를 적용
- 평가지표: MAE, RMSE, RMSLE 많이 사용

- RMSE: MAE에 비해 큰 오류값에 상대적인 패널티를 부과하는 평가 방식.
'Machine Learning > 캐글스터디(파이썬 머신러닝)' 카테고리의 다른 글
| [5장-3] 릿지 회귀, 라소 회귀, 엘라스틱넷 회귀, 선형 회귀모델, 로지스틱 회귀의 이해 (0) | 2023.05.10 |
|---|---|
| [5장-2] 사이킷런 LinearRegression을 이용한 보스턴 주택 가격 예측 (0) | 2023.05.09 |
| [3장-4] 피마 인디언 당뇨병 예측 (0) | 2023.05.07 |
| [4장-2] 앙상블, 랜덤포레스트, 부스팅 (0) | 2023.04.18 |
| [4장-1] 분류(classfication)와 결정트리(decision tree) (0) | 2023.04.13 |