Penguins 자료 중 범주형 변수는 어떤 것들이 있는가?
1. 라이브러리 설치
palmerpenguins
2. 라이브러리 설치
install.packages("palmerpenguins")3. 라이브러리 불러오기
library(palmerpenguins)4. 저장 되어 있는 변수 확인 : ls() 함수 사용
ls(pos=2)[1] "path_to_file" "penguins" "penguins_raw"5. 패키지에 포함된 펭귄 데이터셋 확인
penguins
6. 펭귄 데이터셋에서 종(species)별로 데이터의 빈도를 계산
table(penguins$species) Adelie Chinstrap Gentoo
152 68 1247. island 열에 어떤 값들이 포함되어 있는지, 각 값의 빈도 확인
table(penguins$island) Biscoe Dream Torgersen
168 124 52 8. sex 성별 값 확인
table(penguins$sex)female male
165 168 9. ggplot 라이브러리 설치 및 불러오기
install.packages("ggplot2")library('ggplot2')10. ggplot 패키지를 사용하여 x 축 = species 으로 사용하고, species의 빈도를 막대그래프로 그리기
ggplot(penguins,aes(species))+geom_bar()- ggplot : 객체 생성
- x 축 : species
- geom_bar : 막대그래프

11. TEMP 변수 만들기
TEMP = data.frame(species=names(table(penguins$species)),
+ count=c(table(penguins$species)))- table(penguins$species) : species 열에서 각종 빈도 계산
- names() : table 함수의 결과로부터 species의 이름 추출
- count = : 함수의 결과로부터 추출한 빈도를 count열로 저장
- data.frame() : 위에서 추출한 내용을 TEMP라는 새로운 데이터프레임으로 저장
12. TEMP 변수 확인
TEMP
13. penguins 데이터프레임의 species 열에서 고유한 종들의 이름 추출
names(table(penguins$species))[1] "Adelie" "Chinstrap" "Gentoo" 14. c() : table() 함수의 결과를 벡터로 변환
c(table(penguins$species)) Adelie Chinstrap Gentoo
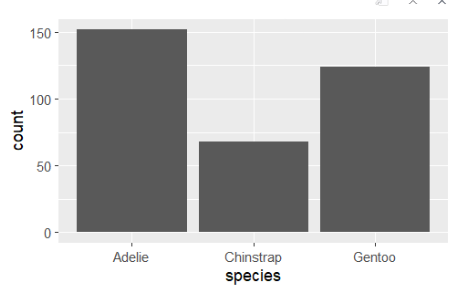
152 68 124 15. species에 따른 빈도를 나타내는 막대 그래프 생성
ggplot(data = TEMP, aes(x = species, y = count)) + geom_bar(stat = 'identity')- data = TEMP
- stat = 'identity' : 막대의 높이를 count값 그대로 사용하도록 지정하는 옵션
16. species에 따른 빈도를 막대그래프로 그리기
ggplot(TEMP,aes(x="", y=count, fill=species))+geom_bar(stat='identity')
17. dim() : 행과 열의 개수 확인
dim(penguins)[1] 344 818. geom_bar() : 막대그래프 그리기
ggplot(penguins,aes(species))+geom_bar()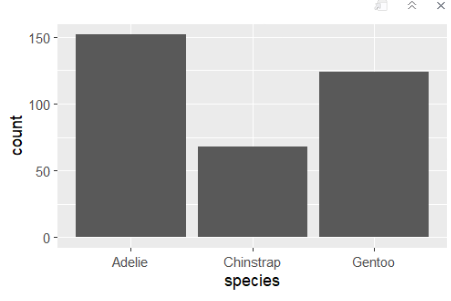
- 성별 추가
ggplot(penguins,aes(species,fill=sex))+geom_bar()
- species에 대한 빈도를 시각화 하는 막대그래프 생성
ggplot(TEMP,aes(x="",y=count,fill=species))+geom_bar(stat='identity')
- coord_polar("y") : 원형 그래프로 변경
ggplot(TEMP,aes(x="",y=count,fill=species))+geom_bar(stat='identity')+coord_polar("y")
bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g의 분포가 species 별로 어 떻게 다른지 알아보려고 한다. 이에 알맞은 그림을 그리고 살펴보시오
19. 산점도
- geom_point() : 각 데이터 포인트를 점으로 표시하는 레이어 추가
ggplot(penguins,aes(species,bill_length_mm))+geom_point()
- geom_jitter() : 산점도에 점으로 표시하되, 겹치지 않도록 약간의 "흩뿌림" 추가
ggplot(penguins,aes(species,bill_length_mm))+geom_jitter()
- geom_boxplot() : 상자 그림으로 데이터의 분포를 시작적으로 표현(데이터의 중앙값, 사분위수, 이상치 표시)
ggplot(penguins, aes(species, bill_length_mm))+geom_boxplot()
- geom_violin() : 분포의 밀도를 더 자세히 표현
ggplot(penguins,aes(species,bill_length_mm))+geom_violin()
- geom_violin()+geom_boxplot()
ggplot(penguins,aes(species,bill_length_mm))+geom_violin()+geom_boxplot()
- width = 0.2 → 상자 그림의 너비 설정, 상자의 폭을 좁게 만든다.
ggplot(penguins,aes(species,bill_length_mm))+geom_violin()+geom_boxplot(width=0.2)
- geom_freqpoly () : 빈도 다각형을 생성하여 연속 데이터의 분포를 시각화함
ggplot(penguins,aes(bill_length_mm,color=species))+geom_freqpoly()
ggplot(penguins,aes(bill_length_mm,color=species))+geom_freqpoly(linewidth=3)
- geom_density() : 밀도 곡선을 생성하여 연속 데이터의 분포를 부드러운 곡선 형태로 시각화
ggplot(penguins,aes(bill_length_mm,color=species))+geom_density()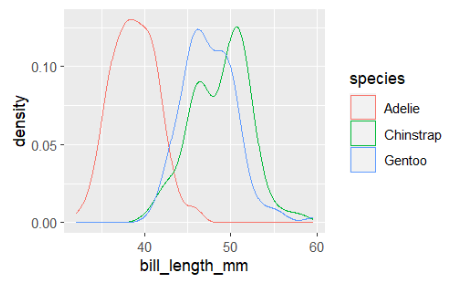
ggplot(penguins,aes(bill_length_mm,color=species))+geom_density(linewidth=3)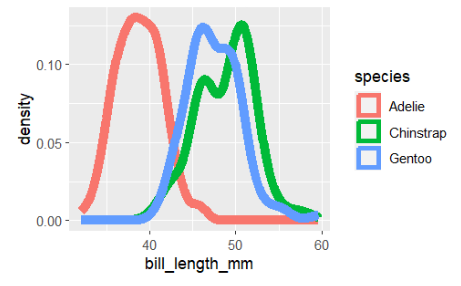
- geom_histogram() : 히스토그램을 생성하여 데이터의 분포를 막대 그래프 형태로 시각화
ggplot(penguins,aes(bill_length_mm,color=species))+geom_histogram()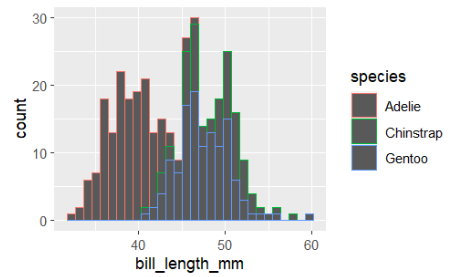
ggplot(penguins,aes(bill_length_mm,color=species))+geom_histogram()+facet_wrap(~species)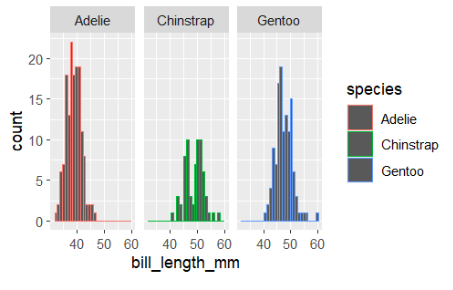
body_mass_g와 나머지 3개의 연속변수들 (bill_length_mm, bill_depth_mm, flipper_length_mm) 의 관계를 알아보려고 한다. 수업시간에 배운 내용을 바탕으로 살펴보시오
- geom_point() : 산점도를 생성하여 두 연속 변수 간의 관계를 점으로 표시하여 시각화
ggplot(penguins, aes(bill_length_mm, body_mass_g))+geom_point()bill_length_mm 과 body_mass_g간의 관계를 산점도로 나타냄

- geom_smooth(method="lm") : 선형 회귀 분석 결과를 시각화 함, method="lm"은 선형 회귀 모델을 사용한다는 것을 의미 → 산점도 위에 선형 회귀 선 표시
ggplot(penguins, aes(bill_length_mm, body_mass_g))+geom_point()+geom_smooth(method="lm")
species별 성별과 island 분포를 살펴보시오.
- ggmosaic : 데이터를 분할하여 범주, 하위 범주, 그룹 간의 관계를 시각화 하는데 사용
→ 다양한 범주로 나뉜 데이터를 모자이크 그래픽으로 표현하면 데이터 패턴을 쉽게 식별 가능
install.packages("ggmosaic")library(ggmosaic)Ptable = table(penguins$species,penguins$island,penguins$sex)- Ptable : 3차원 테이블
- 첫 번째 차원: penguins$species (펭귄 종류)
- 두 번째 차원: penguins$island (서식지 섬)
- 세 번째 차원: penguins$sex (성별)
PtablePdata = as.data.frame(Ptable)Pdatacolnames(Pdata)[1:3] = c("species","island","sex")ggplot(Pdata)+
+ geom_mosaic(aes(x=product(species),weight=Freq,fill=sex))4개의 연속변수를 산점도 행렬을 이용하여 살펴보시오
install.packages("GGally")library(GGally)ggpairs(penguins[,3:6])- ggpairs : 다변량 데이터셋의 변수들 간의 산점도와 히스토그램 동시에 그릴 수 있음
- penguins의 3번째 열부터 6번째 열까지의 변수에 대한 산점도 행렬 그릴 때 사용
'Data visualization > 데이터시각화(R)' 카테고리의 다른 글
| 데이터시각화(R)_Oxboys/faithful (1) | 2023.10.02 |
|---|---|
| 데이터시각화(R)_Diamonds (1) | 2023.09.20 |
| 데이터시각화(R)_Iris Code (0) | 2023.09.15 |
| 데이터시각화 R_ggplot2_Titanic 데이터(범주형 변수) (0) | 2023.09.10 |
| 데이터시각화 R_ggplot2_Tips 데이터 (0) | 2023.09.10 |