Model Selection
▪ Selection of model parameter (capacity) → 모델의 크기를 말함(얼마나 복잡한 것을 썼나)
▪ If we assume a p-order polynomial regressor
To Avoid Overfitting

→ 오버피팅을 피할 수 있는 최적의 학습곡선 (Learning Curve) 찾기

k-fold Cross-Validation
1. Partition data into k-folds
1) Training and testing
• k models with different folds
• Each fold becomes training
data for k-1 times
• Each fold becomes test data
for 1 time
2) Leave-one-out : 데이터가 극단적으로 50개 정도로 적을 때, 49개 학습 후 1개로 평가하는 것을 말함.
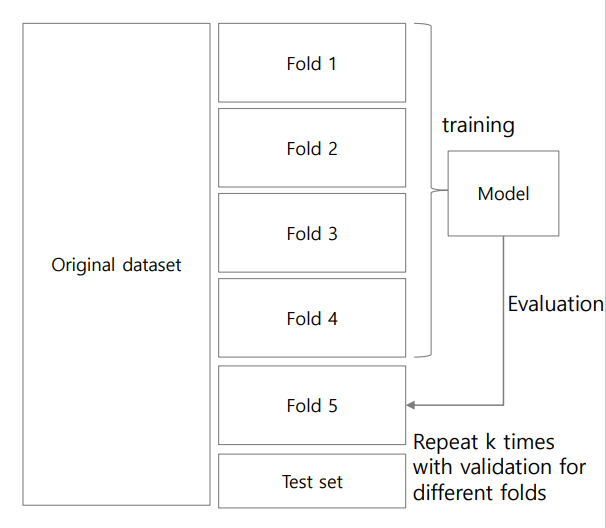
→ 4번 학습 후 1번 평가
Moving Windows(시계열 데이터 일 때)

Regularization(규제)
- 이 방법은 모델에 제약(penalty)을 주는 것 입니다. 쉽게 말하자면, perfect fit 을 포기함으로써(trainging accuracy를 낮춤으로써) potential fit을 증가시키고자(testing accuracy를 높이고자) 하는 것
- 모델 복잡도에 대한 패널티로 Overfitting을 예방하고 일반화 성능을 높인다
(매끄럽지 않은 데이터 설명 함수를 매끄럽게 만들어 모델의 오버피팅을 막기)
'Deep Learning' 카테고리의 다른 글
| 5wk,6wk_Deep Neural Networks (0) | 2024.04.06 |
|---|---|
| 4wk_Neural Networks (0) | 2024.03.30 |
| 2wk_Deep learning (0) | 2024.03.16 |
| 1wk_Early AI 와 Modern AI 차이 (0) | 2024.03.09 |
| Deep Learning /모두를 위한 딥러닝 (무료 강의) (0) | 2024.03.07 |