데이터 해석 및 활용
21. 데이터(data)와 정보(information)에 대한 설명으로 가장 적절한 것은?
① 데이터는 적절한 의사결정의 수단이 될 수 있다.
② 정보란 현실 세계에 존재하는 가공되지 않은 그대로의 값을 의미한다.
③ 정보란 데이터를 처리해서 얻을 수 있는 결과이다.
④ 데이터와 정보는 같은 개념이다.정답: 3번[더보기]
① 데이터(Data)
● 현실 세계에서 단순히 관찰하거나 측정하여 수집한 사실이나 값, 가공되지 않은 그대로의 값
● 의미가 부여되지 않은 객관적 사실
● 가공하기 전 순수한 수치나 기호 자체
● 예시 : 회원의 가입내역, 대리점의 매출내역, 회원의 시스템 로그인 시간 등
② 정보(Information)
● 의사결정에 유용하게 활용할 수 있도록 데이터를 처리한 결과물
● 다양한 정보를 구조화해 유의미한 정보로 분류
● 데이터 간 상관/연관관계 속에서 의미 부여
● 유용성은 상황에 따라 다름
● 예시
▶ 회원의 가입내역을 처리한 회원의 연령별 분포도
▶ 대리점의 매출내역을 처리한 대리점별 평균매출액, 매출이 많은 베스트 대리점 등
▶ 회원의 시스템 로그인을 처리한 회원들이 가장 많이 로그인한 시간대 등
③ 지식(Knowledge)
● 정보를 바탕으로 의사결정에 활용하는 것
● 개인의 경험에 결합해 고유의 지식으로 내재화
● 각자 자기 관점에서 근거 데이터를 업무에 활용
④ 통찰(Insight)
● 지식의 축적과 아이디어가 결합된 창의적인 산물
● 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 창의적인 아이디어
빅데이터의 3대 요소 : 3V
1. 규모(Volume): 데이터의 양
2. 속도(Velocity): 데이터의 수신 및 처리 속도
3. 다양성(Variety): 사용 가능한 데이터 유형의 다양성
22. 데이터의 종류에 대한 설명으로 가장 적절하지 않은 것은?
① 비정형 데이터는 정형 데이터에 비해 분석하기 어렵다.
② 정형 데이터는 주로 XML, HTML, JSON 등의 파일 형 태로 저장된다.
③ 정형 데이터는 테이블의 모든 행에 동일한 열 집합이 존재한다.
④ 비정형 데이터는 특정 스키마가 없는 NoSQL 데이터 베이스가 사용된다.정답: 2번
[더보기]
1) 정형 데이터

▶ 구조화된 데이터, 즉 미리 정해진 구조에 따라 저장된 데이터
▶ 예시 : 표 안에서 행과 열에 의해 지정된 각 칸에 데이터를 저장하는 엑셀의 스프레드시트, 관계 데이
터베이스의 테이블 등
2) 반정형 데이터

▶ 구조에 따라 저장된 데이터지만 정형 데이터와 달리 데이터 내용 안에 설명이 함께 존재함
▶ 따라서 데이터 내용에 대한 설명, 즉 구조를 파악하는 파싱(parsing) 과정이 필요함
▶ 보통 파일 형태로 저장됨
▶ 예시 : 웹에서 데이터를 교환하기 위해 작성하는 HTML, XML, JSON 문서나 웹 로그, 센서 데이터 등
3) 비정형 데이터
▶ 정해진 구조가 없이 저장된 데이터
▶ 예시 : SNS의 텍스트, 이미지, 영상, PDF 문서와 같은 멀티미디어 데이터
▶ SNS 이용률이 크게 높아지면서 실시간으로 많은 양의 비정형 데이터가 생산됨
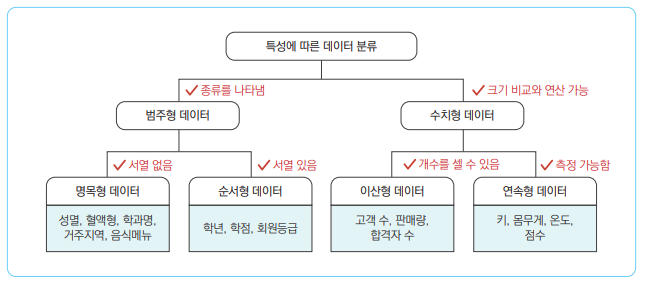
23. 다음 중 수치형의 이산형 데이터의 예시로 가장 적절한 것은?
① 상품의 종류
② 회원의 회원등급
③ 회원의 거주 지역
④ 교통사고 발생 횟수정답: 4번[더보기]
24. 다음 제시된 자료에 대한 기초통계 중 옳은 것은?
10, 20, NULL, 30, NULL
① 평균: 20
② 중앙값: NULL
③ 최빈값: NULL
④ 데이터의 수: 5정답: 1번- 평균 계산: NULL 값은 계산에서 제외되므로, 10 + 20 + 30 = 60이고, 이를 데이터의 수인 3으로 나누면 평균은 20이 됩니다.
- 중앙값: 정렬했을 때 10, 20, 30의 중앙값은 20입니다. 중앙값은 NULL 값을 제외하고 계산합니다.
- 최빈값: 제시된 데이터에서는 반복되는 값이 없으므로 최빈값은 특정할 수 없습니다. 하지만, NULL 자체가 최빈값이 될 수는 없습니다.
- 데이터의 수: NULL 값을 포함하여 총 5개입니다. 하지만, 통계 계산 시 NULL 값은 제외됩니다.
25. 다음 중 연속확률분포에 해당하는 것으로 연결되지 않 은 것은?
① 균등분포, 정규분포
② 정규분포, 지수분포
③ 지수분포, 균등분포
④ 정규분포, 이항분정답: 4번[더보기]
연속확률분포의 종류
▶ 정규분포 : 중심극한정리에 따라 동일한 분포를 가지는 많은 확률변수의 평균 분포를 근사할 수 있는
분포
- 중심극한정리 : 확률분포를 알 수 없는 어떠한 변수라도 정해진 횟수 n만큼 독립적으로 추출하는 작업
을 반복했을 때 추출된 값의 평균은 n이 커짐에 따라 정규분포에 근접함
▶ 감마분포 : a번째 사건이 일어날 때까지 걸리는 시간에 대한 연속확률분포
▶ 지수분포 : 사건이 서로 독립적일 때 사건과 사건 간의 경과시간에 대한 확률분포
▶ 카이제곱분포: k개의 서로 독립적인 표준정규확률변수의 제곱을 합한 값에서 얻어지는 분포
▶ 베타분포: 두 매개변수 α와 β에 따라 [0, 1] 구간에서 정의되는 연속확률분포
▶ 균등분포(균일분포): 특정구간 내의 값들이 나타날 가능성이 균등한 분포
→ 정감지 카베균
이산확률분포의 종류
▶ 베르누이분포 : 결과가 두 가지 중 하나로만 나오는 시행(베르누이시행)이 나타내는 확률분포
▶ 이항분포 : N번의 독립적인 베르누이시행 중 성공횟수의 확률분포로, 베르누이분포는 이항분포의 시
행횟수가 1인 경우에 해당
▶ 기하분포 : 성공확률이 p인 베르누이시행에서 처음 성공이 일어날 때까지 반복한 시행횟수의 확률분포
▶ 음이항분포 : 성공확률이 p인 베르누이시행을 r번 성공할 때까지 반복시행한 횟수의 확률분포로, 기
하분포는 성공횟수 r=1인 음이항분포에 해당
▶ 초기하분포 : N개 중 비복원추출로 n번 추출했을 때 원하는 것이 k개 포함될 확률의 분포
▶ 푸아송(Poisson)분포 : 단위 시간 내에 어떤 사건이 발생하는 횟수를 나타내는 분포
→ 초푸음 베이기
26. 데이터들의 유사도를 측정하여 유사도가 높은 데이터를 그룹화하여 분석하고자 할 때 가장 적절한 데이터 마이 닝 기법은?
① 분류분석
② 군집분석
③ 연관분석
④ 회귀분석정답: 2번
[더보기]
- 연관분석 : 대규모의 데이터 항목 중 유용한 연관성과 상관관계를 찾는 기법
- 군집분석: 집단 또는 범주에 대한 사전 정보가 없는 데이터에 대해 전체를 몇 개의 유사한 집단으로 그룹화하여
각 집단의 성격을 파악하는 기법
- 분류분석: 대표적인 분류분석 기법으로 의사결정나무 기법이 있
- 회귀분석(Regression Analysis) :변수 간의 함수관계를 추구하는 통계적 방법
27. 중앙집중식 데이터베이스와 비교했을 때 분산 데이터베이스의 장점으로 가장 적절하지 않은 것은?
① 데이터베이스 설계가 쉽다.
② 시스템의 성능이 향상된다.
③ 분산제어가 가능하다.
④ 시스템의 확장성이 증가한다정답: 1번
- 시스템의 성능 향상: 데이터를 분산시켜 처리하기 때문에 시스템 전체의 부하를 줄이고 성능을 향상시킬 수 있습니다.
- 분산제어 가능: 지역적으로 분산된 데이터를 각각 제어할 수 있어, 지역 자치성이 보장됩니다.
- 시스템의 확장성 증가: 필요에 따라 시스템의 규모를 점진적으로 확장할 수 있습니다. 이는 비용 효율적이며 유연한 시스템 관리를 가능하게 합니다.
- 분산 데이터베이스의 설계는 중앙집중식 데이터베이스에 비해 더 복잡
28. 다음 중 파일시스템에 대한 설명으로 가장 적절하지 않 은 것은?
① 블록은 파일시스템의 가장 낮은 계층이다.
② 자료의 계층구조는 블록, 파일, 데이터 3가지 주요 계층으로 구성된다.
③ 파일시스템은 자료의 계층구조를 가진다.
④ 파일은 파일명이나 파일 경로 등의 고유한 식별자를 가진다.정답: 2번[자료의 계층구조]
1. 자료의 계층구조 개요
● 파일시스템은 자료의 계층구조를 가지고 있어 데이터를 효율적으로 저장하고 검색할 수 있음
2. 블록(Block)
● 파일시스템의 가장 낮은 계층으로, 블록은 일정한 크기의 데이터 조각으로 파일시스템에 저장됨
● 각 블록은 고유한 주소를 가지고 있으며, 파일시스템은 이러한 블록들을 조직화하여 파일이나 폴더에 할
당함
3. 파일(File)
● 사용자가 생성하는 데이터의 단위
● 파일은 블록들의 집합으로 구성되며, 각 파일은 파일시스템에서 고유한 식별자(파일명 혹은 파일 경로)
를 가짐
● 파일은 데이터와 파일에 대한 메타데이터(파일 크기, 생성 일자, 수정 일자 등)를 포함함
● 파일시스템은 파일의 데이터를 여러 개의 블록에 분산하여 저장하고, 파일의 메타데이터는 특정 블록에
저장되거나 파일시스템의 다른 영역에 저장될 수 있음
4. 디렉토리(Directory)
● 파일이나 다른 디렉토리를 포함할 수 있는 컨테이너 역할을 수행하며, 파일을 조직화하기 위한 계층구조
를 제공함
● 파일시스템에서 각 디렉토리는 고유한 식별자인 디렉토리 경로를 가지며, 사용자는 디렉토리를 통해 파
일에 쉽게 접근할 수 있음
● 파일시스템 내에서 파일의 계층구조를 형성하며, 파일과 다른 하위 디렉토리를 포함할 수 있음
→ 블록, 파일, 디렉토리
29. 데이터베이스 관리 시스템이 등장하게 된 배경으로 가장 적절하지 않은 것은?
① 데이터의 일관성과 무결성을 유지하기 위해 스키마를 정의하고 제약 조건을 설정한다.
② 동시 접근 제어를 위해 트랜잭션 개념을 도입한다.
③ 제한된 데이터 검색 기능을 개선하고자 DBMS 자료의 계층구조를 구성한다.
④ 파일시스템에서는 중복성이 발생할 수 있고, DBMS는 테이블이나 컬렉션과 같은 구조를 사용하여 중복 데이 터를 최소화한다정답: 3번
③ 제한된 데이터 검색 기능을 개선하고자 DBMS 자료의 계층구조를 구성한다:
DBMS의 등장 배경은 데이터의 중복 최소화, 일관성 및 무결성 유지, 동시 접근 제어 등이 주된 이유입니다.
이터 검색 기능의 개선은 DBMS의 중요한 기능 중 하나이지만, '자료의 계층구조를 구성한다'는
표현은 DBMS의 등장 배경을 설명하는 데 있어 직접적이지 않으며,
DBMS의 핵심 목적과는 다소 거리가 있습니다. 따라서, 가장 적절하지 않은 설명은
③ 제한된 데이터 검색 기능을 개선하고자 DBMS 자료의 계층구조를 구성한다입니다.
[더보기]
DBMS 등장배경: 데이터의 중복 최소화, 일관성 및 무결성 유지, 동시 접근 제어
30. 다음 설명에 해당하는 데이터베이스의 구성요소로 가장 적절한 것은?
( )은/는 데이터에 대한 데이터로 데이터의 특성, 구조, 의미 등을 설명하는 정보를 의미한다. 데이터베이스 시스템에서 데이터를 관리하고 사용하기 위해 필요한 정보를 제공하고, 데이터베이스의 보안을 관리하는 데에도 사용된다.
① 메타데이터
② 저장 데이터 관리자
③ 질의처리기
④ 트랜잭션 관리자정답: 1번[더보기]
데이터베이스 구성요소
① 테이블(Table)
● 데이터베이스에서 정보를 구조화하여 저장하는 단위
● 엔터티(Entity) 또는 릴레이션(Relation)이라고도 함
● 행과 열로 구성된 2차원의 구조로, 데이터의 집합을 나타냄
● 각 테이블은 고유한 이름을 가지며, 특정 유형의 데이터를 저장하는 역할을 함
▶ 예 : “학생”이라는 테이블은 학생들의 정보를 저장하는 역할을 할 수 있음
● 일반적으로 관련된 데이터를 그룹화하여 효율적인 데이터 관리를 가능하게 함
② 속성(Attribute)
● 테이블의 열을 나타내며, 특정 데이터 유형에 대한 정보를 기술
● 필드(Field) 또는 변수(Variable)라고도 칭함
● 각 속성은 고유한 이름을 가지며, 해당 속성에 저장되는 데이터의 유형을 정의함
▶ 예 : “이름”, “나이”, “성별”과 같은 속성은 “학생” 테이블에서 각 학생의 이름, 나이, 성별과 관련된 데
이터를 저장함
● 테이블의 구조를 설명하고 데이터의 특징을 정의하는 데 사용
③ 레코드(Record)
● 테이블의 행을 나타내며, 튜플(Tuple)이라고도 함
● 각 레코드는 테이블의 속성에 해당하는 값들의 집합으로 구성됨
▶ 예 : “학생” 테이블의 한 레코드는 특정 학생의 이름, 나이, 성별 등에 대한 값을 포함함
● 데이터베이스에서 개별 데이터 항목을 표현하고 행 단위의 작업을 수행하는 데 사용
④ 메타데이터(Metadata)
● 데이터에 대한 데이터로, 데이터의 특성, 구조, 의미 등을 설명하는 정보를 의미함
● 데이터베이스 시스템에서 데이터를 관리하고 사용하는 데 필요한 정보 제공
● 데이터의 의미와 구조를 설명함
▶ 예 : 테이블의 속성 이름, 데이터 유형, 제약조건, 관계 등의 정보를 포함하며, 이를 통해 데이터의 의
미를 이해하고 해석할 수 있음
● 데이터를 검색하고 조회하는 데 사용됨
▶ 테이블 이름, 속성 이름, 인덱스 정보 등을 포함하여 데이터베이스에서 원하는 데이터를 식별하고 검
색하는 데 도움을 줌
● 데이터베이스의 일관성과 제약조건을 유지하는 데 기여함
▶ 테이블 간의 관계, 제약조건, 외래키 등을 정의하여 데이터의 일관성과 무결성을 보장함
● 데이터를 분석하고 가공하는 데 도움을 줌
▶ 데이터의 유형, 형식, 크기, 통계 정보 등을 포함하여 데이터 분석 및 가공 작업에 필요한 정보를 제공함
● 데이터베이스의 보안 관리에 사용됨
▶ 접근 권한, 사용자 권한, 보안 제약조건의 정보를 포함하여 데이터의 보안과 접근 제어를 관리함
⑤ 데이터 딕셔너리(Data Dictionary)
● 데이터베이스시스템에서 사용되는 데이터 구조와 메타데이터에 대한 정보를 저장하고 관리하는 역할을 함
● 데이터베이스 객체(테이블, 속성, 제약조건 등)의 정의, 구조, 속성, 통계 등의 데이터에 대한 설명과 정보
포함
● 데이터베이스관리시스템(DBMS)에서 중요한 역할을 하며, 데이터의 정확성과 일관성을 유지하는 데 도
움을 줌
⑥ 트랜잭션 관리자(Transaction Manager)
● 데이터베이스에서 트랜잭션의 관리와 제어를 담당하는 역할을 함
● 트랜잭션은 데이터베이스에서 원자와 같은 작업 단위로 간주되며, 여러 개의 데이터 조작 작업을 하나의
논리적인 단위로 묶어 일관성과 안전성을 보장함
● 트랜잭션의 시작, 종료, 병합, 롤백 등의 작업을 처리하여 데이터의 일관성과 동시성 제어를 관리함
⑦ 저장 데이터 관리자
● 데이터베이스의 저장 구조와 데이터의 물리적인 저장, 접근, 관리를 담당하는 역할을 함
● 데이터베이스의 블록 할당, 파일시스템, 인덱스 구조, 버퍼 관리 등을 관리하여 데이터의 효율적인 저장
과 검색을 지원함
● 데이터의 저장 방법과 구조에 대한 결정, 디스크 공간 관리, 인덱스 생성과 유지, 데이터베이스 파일 관
리 등의 작업을 수행함
⑧ 질의 처리기(Query Processor)
● 사용자의 질의(SQL)를 처리하고 데이터베이스로부터 원하는 정보를 추출하는 역할을 함
● 사용자가 요청한 질의를 해석하고, 최적의 실행 계획을 생성하여 데이터베이스로부터 데이터를 검색하
거나 조작함
31. 다음이 설명하는 데이터베이스의 구성요소는? ( )은/는 테이블의 열을 나타내며, 특정 데이터 유형에 대한 정보를 기술한다. 이는 고유한 이름을 가지며, 데이터의 유형을 정의한다. 예를 들어 이름, 나이, 성별 등은 '학생'이라는 테이블에서 해당 구성요소로 사용될 수 있다.
① 레코드(Record)
② 속성(Attribute)
③ 엔터티(Entity)
④ 릴레이션(Relation)정답: 2번
[더보기]
② 속성(Attribute)
● 테이블의 열을 나타내며, 특정 데이터 유형에 대한 정보를 기술
● 필드(Field) 또는 변수(Variable)라고도 칭함
● 각 속성은 고유한 이름을 가지며, 해당 속성에 저장되는 데이터의 유형을 정의함
▶ 예 : “이름”, “나이”, “성별”과 같은 속성은 “학생” 테이블에서 각 학생의 이름, 나이, 성별과 관련된 데
이터를 저장함
● 테이블의 구조를 설명하고 데이터의 특징을 정의하는 데 사용
32. 데이터베이스를 3단계 구조로 구분할 때 해당되지 않는 개념은?
① 개념 스키마
② 내부 스키마
③ 내용 스키마
④ 외부 스키마정답: 3번
외부 스키마 : 사용자나 응용 프로그램의 관점에서 데이터베이스 정의
▶ 특정 사용자 그룹이나 응용 프로그램에 필요한 데이터의 논리적 구조와 접근 방법을 정의
▶ 각각의 외부 스키마는 해당 사용자나 응용 프로그램이 필요로 하는 데이터의 부분집합에 대한 뷰
(View)로서 동작
▶ 데이터베이스 시스템에서 개별적으로 정의되며, 다수의 외부 스키마가 존재할 수 있음
개념 스키마 : 전체 데이터베이스의 논리적 구조 정의
▶ 모든 외부 스키마의 통합된 뷰로서, 데이터베이스의 전체적인 구조와 데이터 간의 관계를 나타냄
▶ 데이터베이스 시스템의 관리 및 조작을 위한 기반을 제공하며, 데이터의 일관성과 무결성을 유지하는
역할을 함
내부 스키마 : 데이터의 물리적 구조 정의
▶ 데이터가 디스크에 저장되는 방식, 인덱스 구조, 저장 위치 등과 같은 물리적 세부 사항 정의
▶ 데이터베이스 시스템의 성능 향상을 위해 최적화된 구조로 데이터를 관리함
→ 외개내
33. 다음 설명에 해당하는 키(Key)로 가장 적절한 것은?
( )는 테이블에서 각 레코드를 고유하게 식별하기 위해 선택된 키이다. 후보키 중에서 선택되고 테이블 내에 서 중복된 값이 없어야하며 NULL 값을 가질 수 없다. 테이블의 주 식별자로 사용되며 테이블의 레코드를 식별하 고 레코드 간의 관계를 구축하는데 사용된다.
① 기본키(Primary Key)
② 대체키(Alternate Key)
③ 슈퍼키(Super Key)
④ 식별키(Identifier Key)정답: 1번
[더보기]
키(Key)
● 데이터베이스에서 레코드를 고유하게 식별하는 역할을 하는 속성(열) 또는 속성들의 조합
● 데이터베이스에서 데이터의 고유성과 무결성을 보장하며, 데이터의 식별 및 검색에 사용
● 대표적인 키의 종류 : 슈퍼키, 후보키, 기본키, 대체키, 외래키
슈퍼키(Super Key) : 테이블 내에서 레코드를 고유하게 식별할 수 있는 속성 또는 속성들의 조합
▶ 테이블 내의 모든 레코드를 고유하게 식별할 수 있지만, 최소성 조건을 만족시키지 않을 수 있음
▶ 테이블의 레코드를 식별할 수 있는 잠재적인 키 집합
- 예 : 책에 대한 정보를 담은 테이블에서 “ISBN”, “ISBN, 책이름”, “ISBN, 책이름, 저자”와 같은 속성들
의 조합은 모두 각 도서를 고유하게 식별할 수 있으므로 모두 해당 테이블의 슈퍼키가 될 수 있음
후보키(Candidate Key) : 테이블에서 각 레코드를 고유하게 식별할 수 있는 속성 또는 속성들의 조합
▶ 슈퍼키의 특징을 가지면서도 최소성 조건을 만족함
▶ 테이블의 레코드를 고유하게 식별할 수 있는 최소한의 속성 집합
▶ 후보키는 기본키로 사용될 수 있는 집합으로, 후보키 중에서 기본키를 선택함
- 예 : 책에 대한 정보를 담은 테이블에서 “ISBN”, “책이름, 저자”와 같은 속성들의 조합은 각 도서를 고
유하게 식별할 수 있는 최소한의 속성이므로 해당 테이블의 후보키가 될 수 있음
기본키(Primary Key) : 테이블에서 각 레코드를 고유하게 식별하기 위해 선택된 키
▶ 후보키 중에서 선택되며, 테이블 내에서 중복된 값이 없어야 하고 NULL 값을 가질 수 없음
- NULL : 프로그래밍 언어에서 아무 값도 갖지 않는 경우를 의미로, 0 또는 공백과 다름
▶ 테이블의 주 식별자로 사용되며, 테이블의 레코드를 식별하고 레코드 간의 관계 구축에 사용
- 예 : 책에 대한 정보를 담은 테이블에서 “ISBN”과 “책이름, 저자”의 두 가지 후보키 중 하나를 기본키
로 설정하여 각 레코드를 고유하게 식별할 수 있음
대체키(Alternate Key) : 기본키가 될 수 있는 후보키 중 기본키로 사용되지 않는 키
▶ 테이블의 레코드를 고유하게 식별할 수 있는 속성 집합이지만, 기본키로 선택되지 않은 경우 사용됨
- 예 : 책에 대한 정보를 담은 테이블에서 “책이름, 저자”를 기본키로 설정한다면, “ISBN”은 대체키가 됨
외래키(Foreign Key) : 한 테이블에서 다른 테이블의 기본키를 참조하는 키
▶ 외래키를 사용하여 테이블 간의 관계를 맺을 수 있으며, 참조 무결성을 유지할 수 있음
▶ 테이블 간의 관계를 정의하고 데이터의 일관성을 유지하는 데 사용됨
▶ 다른 테이블의 기본키와 연결되며, 참조하는 테이블의 레코드를 참조하는 제약조건을 가짐
34. 다음 중 데이터를 병합하는 명령어에 해당하는 것은?
① INNER JOIN ② SELECT ③ GROUP BY ④ ORDER BY정답: 1번35. 데이터 보안 방식 중 데이터 접근을 제어하는 방식에 해당하는 것은?
① 전송 중 데이터 암호화
② 데이터 저장 프로세스 추적
③ 역할에 따라 데이터 사용 권한 할당
④ 정기적인 백업 및 복구 절차정답: 3번
데이터 접근 제어 방식
- 역할에 따라 데이터 사용 권한 할당: 사용자의 역할이나 직무에 따라 데이터에 대한 접근 권한을 다르게 설정하여, 데이터의 보안성을 달성하는 방법입니다. 이는 사용자가 필요한 데이터에만 접근할 수 있도록 하여, 불필요한 데이터 노출을 방지합니다.
36. 웹 스크래핑에 관한 설명으로 가장 적절한 것은?
① 웹사이트에서 데이터를 추출하는 과정이다.
② 웹사이트의 보안을 강화하는 과정이다.
③ 웹사이트의 트래픽을 생성하는 과정이다.
④ 웹사이트의 디자인 미학을 개선하는 과정이다정답: 1번37. NoSQL 데이터베이스의 특징에 대한 설명으로 가장 적절한 것은?
① 데이터 저장을 위해 미리 정의된 스키마를 제공한다.
② 데이터 쿼리를 위해 주로 SQL을 사용한다.
③ 구조적 및 관계형 데이터를 처리하는 데 적합하다.
④ 유연한 스키마 설계를 제공하고 비정형 또는 반정형 데이터를 처리한다.정답: 4번
NoSQL 데이터베이스의 주요 특징
유연한 스키마 설계: NoSQL 데이터베이스는 미리 정의된 스키마 없이도 데이터를 저장할 수 있어, 데이터 구조가 시간에 따라 변할 수 있는 애플리케이션에 적합합니다.
이로 인해 개발자는 데이터베이스를 더 빠르고 유연하게 사용할 수 있습니다.
비정형 또는 반정형 데이터 처리: NoSQL은 다양한 데이터 형식을 저장하고 관리할 수 있으며, 이는 특히 비정형 데이터나 반정형 데이터를 다루는 데 유용합니다.[더보기]
데이터 저장
▶ 관계형 데이터베이스 : 구조화된 데이터를 저장
- 대표적인 솔루션 : MySQL, PostgreSQL, Oracle 등
▶ NoSQL 데이터베이스 : 비정형 또는 반정형 데이터를 저장
- 대표적인 솔루션 : MongoDB, Cassandra, Redis 등
▶ 데이터웨어하우스 : 다양한 소스에서 수집된 대량의 데이터를 저장, 관리 및 분석하도록 설계된 중앙
저장소로, 비즈니스 인텔리전스를 위한 플랫폼
- 대표적인 솔루션 : Amazon Redshift, Google BigQuery, Snowflake 등
▶ 분산 파일시스템 : 대량의 비정형 데이터를 저장
- 대표적인 솔루션 : HDFS(Hadoop Distributed File System), Amazon S 등
38. 데이터 관리에서 데이터 무결성 검증과 관련된 설명으로 가장 적절한 것은?
① 데이터의 정확성, 완전성, 일관성을 보장하기 위해 실시한다.
② 데이터 압축을 통해 스토리지 요구사항을 감소시킨다.
③ 민감한 정보를 보호하기 위해 데이터를 암호화한다.
④ 분석을 위해 표준화된 형식으로 데이터를 변환한다.정답: 1번39. 조직에서 비즈니스 인텔리전스를 활용하는 목적으로 가장 적절하지 않은 것은?
① 데이터 보안 및 개인정보 보호 조치 강화
② 일상적인 비즈니스 프로세스의 자동화
③ 데이터 기반 의사결정의 지원과 실행 가능한 통찰 제공
④ 마케팅 전략 개발 및 실행정답: 1번40. 비즈니스 인텔리전스 구현의 이점으로 가장 적절한 것은?
① 데이터 복잡성 및 혼란 증가
② 데이터 분석 및 보고의 필요성 감소
③ 의사결정 능력 및 전략적 통찰 향상
④ 데이터에 대한 제한된 접근 및 정보 흐름정답: 3번'경영정보시각화능력' 카테고리의 다른 글
| 경영정보시각화능력 필기 후기/ Tip 공유 (0) | 2024.05.19 |
|---|---|
| 경영정보시각화능력_B형 오답 정리 (0) | 2024.05.18 |
| 경영정보 일반 A형_문제풀이 41~60번 (0) | 2024.03.24 |
| 경영정보 일반 A형_문제풀이 1~20번 (0) | 2024.03.20 |