합성곱 신경망(Convolutional Neural Networks, CNN)의 핵심 개념 중 하나는 데이터와 합성곱 필터(커널) 간의 행렬 곱셈을 통한 특징 추출입니다. 여기서 주요 차이점은 다음과 같습니다:
- 희소 연결(Sparse Connection): CNN에서 필터는 입력 데이터의 그리드와 같은 로컬 데이터에만 연결되어 있어, 전체 데이터 대신 특정 지역의 특징을 추출하게 됩니다. 이러한 방식은 전체 데이터를 고려하는 대신, 중요하다고 생각되는 부분에 집중하여 필터링합니다. 이는 계산 효율성을 높이고, 데이터 내 중요 정보에 대한 집중력을 향상시키는 특징을 가집니다.
- 파라미터 공유(Parameter Sharing): 합성곱 신경망에서 동일한 필터가 입력 이미지의 모든 픽셀에 적용됩니다. 이는 모든 위치에서 동일한 특징을 찾아내며, 이 과정을 통해 네트워크의 가중치 수를 크게 줄일 수 있습니다. 모든 픽셀에서 동일한 패턴이나 특징을 감지하는 데 필요한 파라미터를 하나만 학습함으로써 메모리 사용을 줄이고, 계산 효율성을 높입니다.
- 표현 학습(Feature Learning): 필터는 원본 이미지에서 중요한 특징이나 패턴을 찾아내고, 이를 통해 이미지를 대표하는 정보를 학습합니다. 합성곱 필터가 이러한 특징을 성공적으로 학습할 경우, CNN은 다양한 이미지에 존재하는 유사한 특징을 감지하고, 이를 활용하여 분류, 인식, 분석 등의 과제를 수행할 수 있습니다.
이러한 원리들은 CNN이 이미지와 같은 고차원 데이터에서 유의미한 특징을 효과적으로 추출하고, 더 적은 파라미터로 복잡한 데이터를 모델링할 수 있도록 합니다. 희소 연결과 파라미터 공유는 CNN이 이미지 인식과 분류에서 뛰어난 성능을 발휘하는 데 중요한 역할을 하며, 표현 학습은 CNN이 입력 데이터의 복잡한 구조를 이해하고 추상화하는 능력을 가능하게 합니다.
Matrix multiplication by data and convolutional filter (kernel)
Main difference
• A filter affects the grid-like local data (sparse connection) / 필터는 그리드 형태의 로컬 데이터에 영향을 미칩니다(희소 연결)
• A filter is used for the entire pixels of image (parameter sharing) / 이미지 전체 픽셀에 필터 사용(파라미터 공유)
• A filter finds one representation for original image
다차원 입력에 대한 합성곱 연산: CNN은 다차원의 입력 데이터를 처리하는데, 이는 일반적으로 이미지 데이터의 너비, 높이, 채널(예: RGB 색상 채널)을 포함합니다. 각 차원은 데이터의 다른 특성을 나타냅니다.
합성곱 연산의 특징:
- 스파스 연결(Sparse Connection): 필터는 입력 데이터의 일부 영역에만 연결되어, 중요한 특징을 추출합니다.
- 파라미터 공유(Parameter Sharing): 동일한 필터가 이미지 전체에 걸쳐 사용되어 파라미터 수를 줄이고, 모델의 효율성을 증가시킵니다.
- 표현 학습: 필터는 원본 이미지로부터 특징을 추출하고, 이를 통해 이미지를 대표하는 정보를 학습합니다.
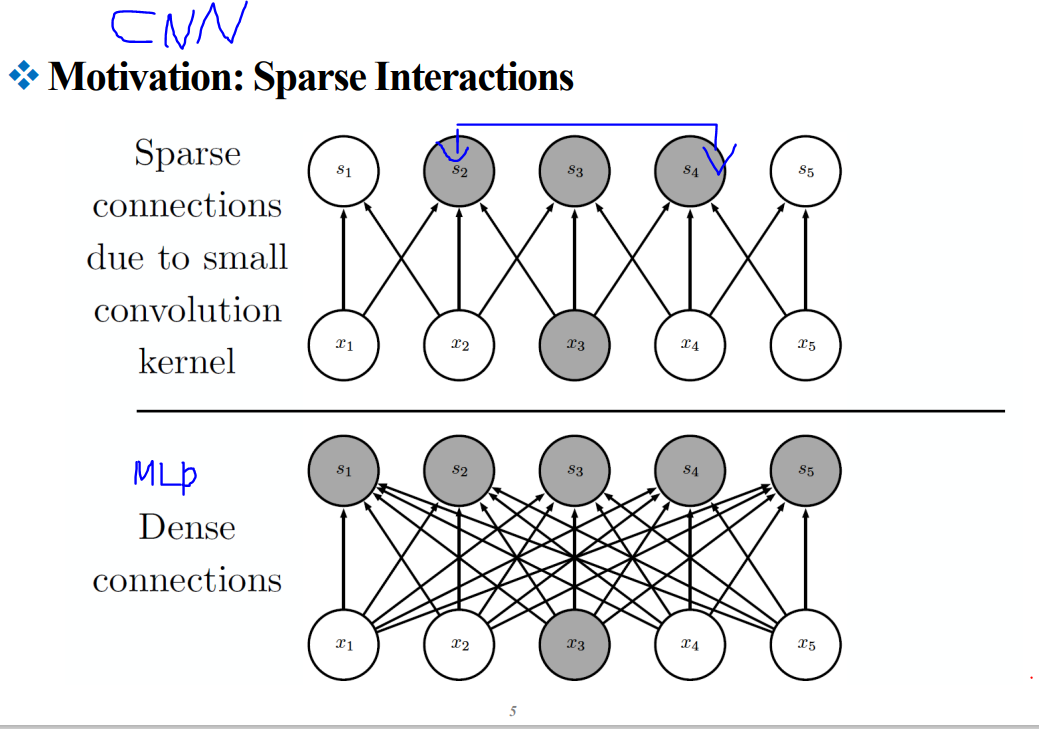
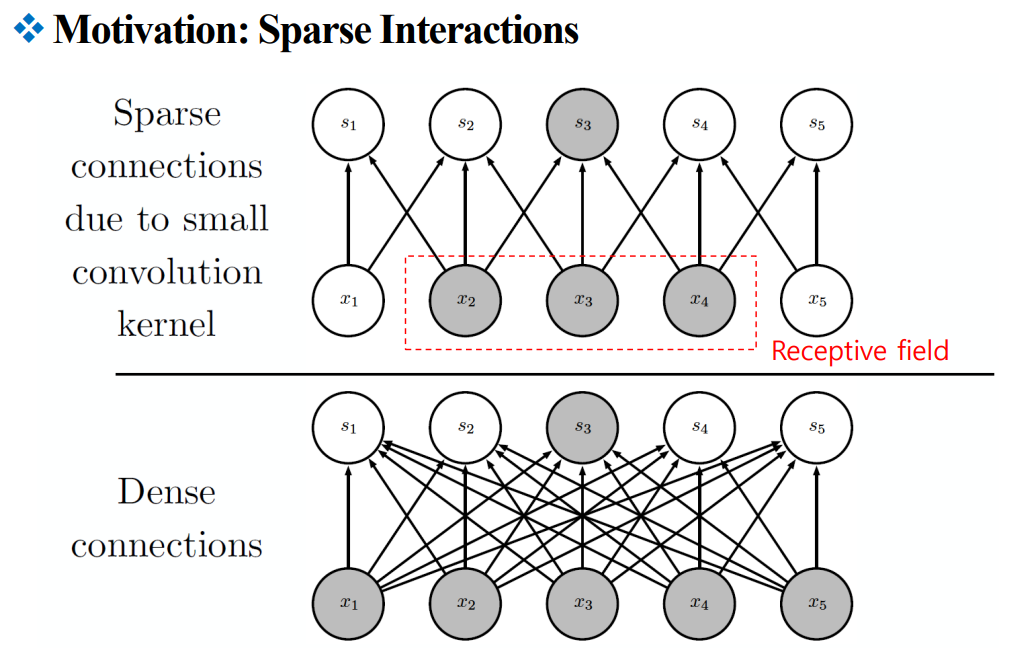
컨볼루셔널 뉴럴 네트워크(CNN)에서 사용되는 "Sparse Interactions" 또는 희소 상호작용을 설명하는 것 같습니다.
이미지의 상단에는 컨볼루션 커널이 작을 때 발생하는 희소 연결이 표시되어 있고, 그 결과 입력 층의 한 부분이 주변의 작은 영역에만 영향을 미치는 것을 보여주고 있습니다. 이는 'Receptive field'라는 박스 안에 있는 영역으로 표시되어 있습니다.
반면, 이미지 하단에는 전통적인 밀집 연결 신경망을 보여주고 있습니다. 여기서는 모든 입력 노드가 출력 노드의 각각과 연결되어 있으며, 이는 훨씬 더 많은 파라미터와 계산을 필요로 합니다.
이러한 희소 연결 구조는 CNN이 이미지 인식과 같은 작업에서 강력하게 작동하는 이유 중 하나입니다. 커널을 통한 슬라이딩 윈도우 방식의 처리는 입력 이미지의 지역적 특성을 효과적으로 잡아내며, 이는 결과적으로 매개변수의 수와 계산량을 줄여줍니다

→ g3가 x의 전체를 보고 있다.

풀링 연산: 풀링은 합성곱 레이어의 출력을 간소화하여 데이터의 크기를 줄이고, 중요한 정보를 보존하는 과정입니다. 다양한 풀링 방법이 있으며, 가장 흔히 사용되는 방법은 최대 풀링입니다.
▪ 비선형 활성화 값의 출력 수정
▪ 특정 위치의 네트 출력을 인근 출력의 요약 통계
→ 85% Max pooling 사용, 나머지 Average Pooling 사용
▪ 풀링
- 역전파: 활성화된 가장 큰 인덱스만 유지합니다.
▪ 풀링이 꼭 필요한가?
- 풀링과 전환 큰 걸음으로
채널별 풀링(Channel-wise Pooling): 컨볼루셔널 신경망에서 특징 맵(feature maps) 각각에 대해 독립적으로 풀링 연산을 적용하는 것
→ 이 방법은 각각의 특징 맵에서 가장 두드러진 특징을 추출하는 데 도움이 됨.
예를 들어, 최대 풀링(max pooling)은 특정 영역 내에서 가장 큰 값을 선택하여 해당 채널의 특징을 대표하게 합니다.

컨볼루셔널 신경망(CNN)의 레이어 구조를 두 가지 방식으로 표현한 것입니다. 오른쪽은 '단순 레이어 용어(Simple layer terminology)'로 각 단계를 더 단순화하여 표현한 것이고, 왼쪽은 '복잡한 레이어 용어(Complex layer terminology)'로 각 단계가 좀 더 구체적으로 나타나 있습니다.
단순 레이어 용어에서는 다음과 같이 나타내죠:
- Convolution layer: 입력에 대해 컨볼루션(합성곱) 연산을 적용하는 단계.
- Detector layer: 활성화 함수를 적용해 비선형성을 부여하는 단계, 여기서는 예로 Rectified Linear Unit(ReLU) 함수를 사용하는 것을 언급하고 있어요.
- Pooling layer: 특징 맵에서 특정 영역에 대한 요약 정보(예: 최대값)를 취해 데이터의 차원을 축소시키는 단계입니다.
복잡한 레이어 용어에서는 같은 구성 요소들을 좀 더 세분화하여 설명합니다:
- Convolution stage: 위와 같으나 '단계'라는 용어를 사용하여 컨볼루션 과정이 연속적인 단계의 일부임을 나타냅니다.
- Detector stage: 비선형 단계를 좀 더 구체적으로 '단계'로 지칭합니다.
- Pooling stage: 풀링이 하나의 단계로 표현되는 것이 아니라, 전체 컨볼루션 레이어 안에서의 한 부분으로 나타나 있어요.
이러한 표현은 문맥에 따라 사용자의 이해를 돕기 위해 조절될 수 있습니다. 특히, 이해하기 쉬운 방식으로 표현하는 것이 중요한 초보자나 일반 대중에게는 '단순 레이어 용어'가 더 적합할 수 있어요.
Zero-padding

제로 패딩(zero padding)은 컨볼루셔널 신경망에서 이미지 또는 데이터의 테두리에 0의 값을 추가하는 과정입니다. 이것은 컨볼루션 연산을 수행할 때 입력 데이터의 크기를 유지하도록 도와주며, 데이터의 가장자리에 있는 정보가 중심에 있는 정보만큼 충분히 활용될 수 있도록 합니다.
제로 패딩에는 몇 가지 중요한 이유가 있습니다:
- 크기 유지: 컨볼루션을 수행하면 출력의 크기가 줄어들 수 있는데, 패딩을 추가함으로써 입력 데이터의 공간적 차원을 보존할 수 있습니다.
- 정보 손실 방지: 패딩 없이 컨볼루션을 수행하면 데이터의 가장자리 부분이 충분히 활용되지 못하고 손실될 수 있습니다. 제로 패딩을 사용하면 가장자리 정보도 중앙의 정보만큼 반복해서 사용될 수 있어서 정보의 손실을 줄일 수 있습니다.
- 디자인 유연성: 패딩을 통해 네트워크 설계자는 출력 데이터의 크기를 더 잘 제어할 수 있으며, 다양한 컨볼루션 레이어 디자인을 실험할 수 있습니다.
예를 들어, stride는 컨볼루션 필터가 입력 데이터를 지나가면서 건너뛰는 간격을 말하고, w/o padding는 패딩 없이 컨볼루션 연산을 수행하는 것을, w/ padding은 패딩을 적용한 상태에서 컨볼루션 연산을 수행하는 것을 의미합니다.
기본 합성곱 함수의 변형:
- 스트라이드(Strides): 필터가 입력 데이터를 통과하는 간격을 의미합니다.
- 제로 패딩(Zero Padding): 입력 데이터 주변을 가상의 '0'으로 채워 넣어서 필터가 데이터의 가장자리에서도 동일하게 작동하도록 합니다.
주목할 만한 CNN 아키텍처들:
- LeNet: CNN의 초기 모델 중 하나로, 손글씨 숫자 인식에 사용되었습니다.
- AlexNet: 이미지 분류에서 뛰어난 성능을 보인 모델로, 딥러닝의 가능성을 널리 알린 계기가 되었습니다.
- VGGNet: 깊이(depth)가 매우 깊은 모델로, 일관된 합성곱 레이어 구조를 사용합니다.
- GoogleNet(인셉션 모델): 복수의 필터 사이즈를 병렬적으로 사용하며, 계산 효율을 높이고 더 나은 특징을 학습할 수 있게 설계되었습니다.
- ResNet: 잔차 네트워크로, 스킵 연결(skip connections)을 통해 그래디언트 소실 문제를 해결합니다.
- DenseNet: 각 레이어가 이전 모든 레이어와 연결되어 특징 재사용을 장려하고, 그래디언트 소실 문제를 방지합니다.
'Deep Learning' 카테고리의 다른 글
| 2-1. Generative Models (1) | 2024.05.02 |
|---|---|
| "7wk_Convolutional Neural Networks(구조 파악) (0) | 2024.04.21 |
| 5wk,6wk_Deep Neural Networks (0) | 2024.04.06 |
| 4wk_Neural Networks (0) | 2024.03.30 |
| 3wk_Machine Learning Basic (0) | 2024.03.23 |