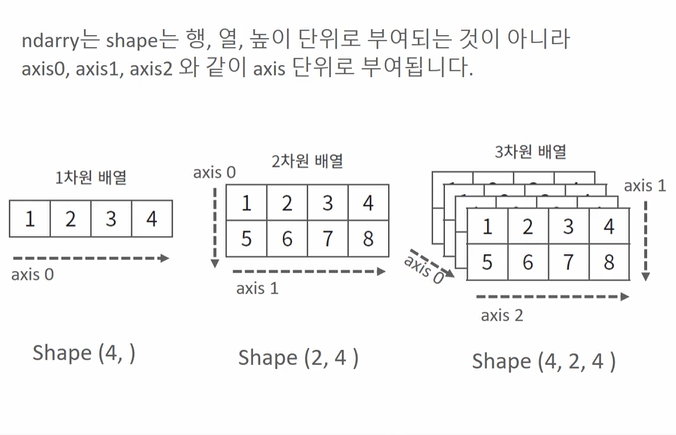
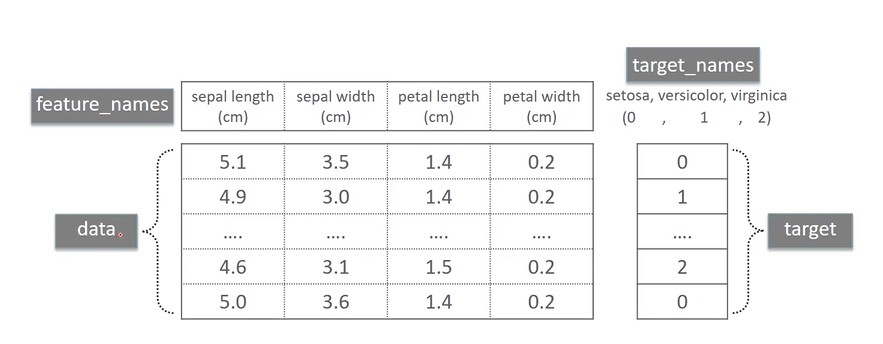
분류 - 학습 데이터로 주어진 데이터의 피처와 레이블값을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측하는 것 분류를 구현할 수 있는 다양한 머신러닝 알고리즘 베이즈(Bayes) 통계와 생성 모델에 기반한 나이브 베이즈(Naive Bayes) 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀(Logistic Regression) 데이터 균일도에 다른 규칙 기반의 결정 트리(Decision Tree) 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신(Support Vector Machine) 근접 거리를 기준으로 하는 최소 근접(Nearest Neighbor) 알고리즘 심층 연결 기반의 신경망(Neural..